coala
Welcome to The coala Blog!
This post is going to be more like an acknowledgement, just so you know.
5 years. 5 fucking years. That's a really long time for anyone to wait before restarting a hobby they considered an important stress buster in their life. That's what this blog is for me. Or atleast was, until the September of 2017.
After tackling everything that life had to throw at me for the past 5 years, my plans for this creative space have changed. What this blog will now be, is a memoir, a nonfictional, honest and frank retelling/recollection of several events in my life - my past, the present, and the several lessons I learned from it. To the readers who are tuning in just now, thank you for doing so. Please don't be fooled by the past 5 posts. I cringe at them even today. From this point onwards, you guys are in for an interesting/fucked up read, depending on how you decide to look at it. About time I gave this a shot.
Great startup teams can be found in unusual places because they are less likely to be looking for a standard career path. Yes, the purpose of a business is to make a profit, retain customers, be sustainable, and, for some, make a difference in the community. But, none of this is possible without a collaborative effort; continually gathering intellect to become smarter, better and more effective.
Remote work is no longer work these days. We catch up for quick meetings and coffee breaks online. In a company that manages minds, people need to take responsibility for learning what they need to know and do. This means that they need to be aware of what they’re doing now and what they may be called upon to do in the future. They need to know what is relevant for them to learn and be empowered to learn what is necessary today and in preparation for tomorrow. They need to understand that what they learn will help the company meet its business goals. They must be able to develop and maintain their own learning plans and portfolios, and be prepared to act as teachers and mentors for other people in the company. Independent learners are capable of successfully meeting the requirements of learning projects they choose, whether it’s completion and a passing grade, measures of competency, or an actual project deliverable.
Learning is not the result of a program; it is ingrained in the culture of an organization. A learning culture is expressed in the assumptions, values, environment, and behaviors of the organization. To learn, people must have a growth mindset. Learning must be valued and advocated throughout the organization. Learning must be reflected in the routines and rituals of employees. The physical setting must create an environment that supports learning. Asking questions, giving feedback, and encouraging debate and alternate viewpoints must be the routine activity of the organization. This is even more powerful when its leaders and managers ask questions, listen deeply, and follow-up with action. Sharing successes and failures are done openly and without disapproval. Employees tell stories to draw lessons and learn from their experiences. Action-learning is essentially part of how people do their work. Managers encourage their direct reports to acquire new knowledge and skills and apply that learning throughout the organization. They advocate for collaboration in teams that promote psychological safety. The work environment is one of respect and trust and transparency. People do not feel harassed, teased, and bullied. They are not ignored and marginalized. Importantly, people deeply listen to each other. Feedback is considered an opportunity to develop and grow; an occasion for learning. A learning culture is all of this and more. An organization that is creating and maintaining a learning culture, is truly ready to compete in the world today.
These are the bonds that held us together. Being respectful of each other, reaching out for help and being reliant on one another.
How we stuck together. was originally published in My New Roots.. on Medium, where people are continuing the conversation by highlighting and responding to this story.
Under Construction
For the final stretch of GSoC, the final tasks were completed/are being completed.
1) Polished my existing work on spyder-coala, SublimeLinter-coala, syntastic-coala.
This also included writing docs and making sure that the plugins could be installed and run properly.
Further, I added gifs/images to show the usage of each of the above plugins in the repository.
2) For the package manager repository, work is being done on adding AtomDependency which is the dependency manager for apm.
3) Work is being done on the report which can be found here. Aside from writing the report itself, this involves gathering commits which were worked on during the GSoC period, listing milestones, and more. In other words, it summarizes my work during the GSoC period.
Time for the final phase of GSoC. A rough outline of the things I’m working on during this phase are:
1) Polishing my existing work on coala-spyder, coala-sublime, coala-syntastic and transferring repos to the coala organisation.
This may include bug fixing, adding small new features, writing tests and making sure CI builds are passing.
2) Looking into coala-atom and coala-onivim (new, which might be have resuable code from coala-syntastic) if it works out.
3) Starting work on the packager-manager repo as my mentor mentioned in the previous blog posts of phase-2.
There was a bit of a slowdown to this phase due to a series of interviews that I had to give, so I’ll have to pick up the pace from this point onwards. A majority of the work that was planned to be completed in this phase will be moved to phase-3.
My strategy for proceeding is laid out as follows:
1) For the remainder of the Phase-2 days, I plan to integrate coala within sublime text using SublimeLinter. The current state for this plugin is included in the readme here alongside the code.
Through regex, we capture the output of coala in the console as depicted below:

to be shown as:

2) Understand documentation of the dependency_management repo in preparation for phase 3 to ensure that the package managers are being properly installed.
There was a bit of a slowdown to this phase due to a series of interviews that I had to give, so I’ll have to pick up the pace from this point onwards. A majority of the work that was planned to be completed in this phase will be moved to phase-3.
My strategy for proceeding is laid out as follows:
1) For the remainder of the Phase-2 days, I plan to integrate coala within sublime text using SublimeLinter. 2) Go through documentation of the dependency_management repo in preparation for phase 3 to ensure that the package managers are being properly installed.
After a talk with my mentor, John, I obtained a few hints on the right direction and which
activities would prove to be most useful in helping coala as an organization.
First off, my existing work on coala-spyder from the previous phase will be reported to the spyder community and an advanced copy of my previous blog posts will be
provided to them, if furthering that mission is important to them. If not, we can still maintain coala-spyder as a
repository within coala.
Moving onto issues that’re of more importance to coala, we have a major problem where plugins are built and abandoned quite often. To
ensure maintenance, if we take a step back to ensure that the package managers and the actual frameworks are being installed
without issues, we can say with some degree of certainty that the plugin will work properly.
Work done in this phase will involve a series of bug fixing on existing coala plugins to make sure that they are in a working state
before proceeding further.
This part follows from my previous blog post where I set up the python-QT widget. I now integrate the previously
created widget into the spyder IDE and also work on setting up continuous integration and unittests by using pytest.
During this phase we’re working on building coala-spyder.
Main components of this widget to ensure it’s working correctly are:


This part involved integrating our widget into the actual spyder-ide, and also being able to run it from the menu
and setting up a shortcut key-binding to envoke it.
Relevant changes: 15aab50
Areas have been identified for which tests need to be created. This includes writing some unittests which test the
functions of the expected output of our single file for which we are running coala on, the widgets and the interface
between the spyder-ide and our widget i.e. the plugin. Complete coverage for this has not yet been achieved.
Relevant changes: 63d0a51
The continuous integration environment has successfully been setup to run tests which are created for coala spyder.
For this I have chosen to use travis-CI and I have setup the required .travis.yml configuration file.

READMEs are likely the single most overlooked component of a promising new open source repository. You could have the most amazing project the world has ever seen, but if you don’t leave a good first impression, it won’t be seen. In this article, we’ll look at some of the best practices when it comes to creating a README, and wrap up with a look at some great examples out in the wild. Following these tips in your own projects will help catch the attention of visitors and lead to more users and contributors.
In the world of open source development, there’s been a subtle trend toward cute names that don’t describe a project at all, something like “bacon” for a JavaScript graphing library (just to provide a random example). If, for some reason, you think bacon is a good analogy to the way in which your graphing library functions, perfect! Use it! But if not, try finding another word (or make one up) which may describe it better.
A perfect example that comes to mind is Vue. It’s three letters, highly memorable, and very descriptive of the project, despite not being an actual word.
Really, you can style your title however you feel fits best. I like using lowercase for my repository names, but title case in my READMEs. That’s not everyone’s preference though, and, frankly, it doesn’t matter all that much.
What matters much more is a short description of what your project/library does. Put this description right under your title, before any badges, links, or anything else. Consider this the TL;DR of your repository, and try to keep it under two sentences. For new visitors to your repository, this is going to be their absolute first impression of what your project does — don’t confuse them with unnecessary jargon!

Badges are small, colorful tags that you can put in your README to show off things like whether your tests are passing, test coverage, technologies used, and various other metadata about your repository. For a full list of the most common badges and an easy interface to create your own, check out the Shields.io website. It even lets you create your own!
Having badges is good. Having three lines of repetitive badges, on the other hand, may be a little excessive and can overwhelm readers, drawing them away from the important details in your document. In my experience, 2–5 badges is ideal. Anything more than that might be better suited further down in your document, and certainly doesn’t belong at the top. Choose only the most important badges to feature in the prime real-estate at the top of your README.
Nice logos can really make your README stand out from the rest. There are a few places you can put them: above your title, below your title, on the right next to your title, or really anywhere you find is nice and not too distracting. If your logo includes the title of your project, consider using it instead of a title, but remember to add alt text so that screen readers can still pick up on it.

Pictures or screenshots of your project (if applicable) are potentially one of the most important things you can include in your README. For people unfamiliar with the project (or who aren’t quite sure if they want to use it), showing off what it looks like in practice can be very beneficial. If possible, scatter these pictures throughout the README, but try to have one somewhere near the top to help hook in new visitors.
If you can’t easily take screenshots of the thing you’re developing (like a non-graphics library or package), try to include a link to a CodePen or other fiddle website so that users can see it in action and play around without installing it.
It’s often nice to include short, clean, and well documented snippets of code in your README to show users what it might be like to use your library or package. Showing the result of the code in the form of a screenshot or link is also a big plus.
In order to be effective, your code samples should be well documented, with comments and descriptions before and after about what the code does. Assume the reader is not an expert on your code, because they likely aren’t. Again, keep the code samples short and use them sparingly.
If your README is written in Markdown (in other words, a .md extension), you can mix in some HTML where it may be convenient. Usually using plain Markdown is plenty, but if you want to get fancy with centered titles or images, you’re going to need to get your hands dirty with a little HTML. Take the following example:

Looks pretty snazzy, right? Here’s the relevant part of the README.md:
<h1 align="center">GitPoint</h1> <br>
<p align="center">
<a href="https://gitpoint.co/">
<img alt="GitPoint" title="GitPoint" src="http://i.imgur.com/VShxJHs.png" width="450">
</a>
</p>
<p align="center">
GitHub in your pocket. Built with React Native.
</p>
<p align="center">
<a href="https://itunes.apple.com/us/app/gitpoint/id1251245162">
<img alt="Download on the App Store" title="App Store" src="http://i.imgur.com/0n2zqHD.png" width="140">
</a>
<a href="https://play.google.com/store/apps/details?id=com.gitpoint">
<img alt="Get it on Google Play" title="Google Play" src="http://i.imgur.com/mtGRPuM.png" width="140">
</a>
</p>
Although not everything is allowed in this custom HTML (you can’t use custom styles, for example), it should still provide you with a fair amount of flexibility in order to format your README to your heart’s content.
While that picture above looks phenomenal with the default GitHub color scheme, several browser extensions add a dark theme. Let’s see what it looks like with the GitHub Dark Theme Chrome extension enabled:

It’s alright, but definitely not as nice as a transparent background. Obviously, a majority of the people visiting your repository won’t have a customized theme, but it’s nice to be inclusive and thoughtful of those who do, especially since it’s often very little work on your part.
Every author and every developer has their own unique style. This includes all the writing and styling that goes into a README. You definitely don’t have to conform to every rule about READMEs, and the suggestions I gave in this article are likely different than the suggestions other might give. In the end, how you present your hard work is up to you, but hopefully this article gave you some good things to consider.
Here are just a few repositories (found on GitHub Trending) with very well executed READMEs.
This phase mainly comprises of work being done with spyder.
In order to integrate coala within spyder, we had to follow 4 major steps.
During this phase we’re working on building coala-spyder.
This GUI interface can be independently tested as a stand-alone entity.

Main components of this widget to ensure it’s working correctly were:
coala onTo realise this part, I modified run_coala_with_specific_file
to create a desired output that would support spyder and QT for the format which could be parsed with ease using regex. I also went through
documentation extensively of relevant python-QT components for creating the GUI, following the structure of existing plugins developed for spyder.
Relevant commits: 3336053 | 04f288e | 6a58e83 | 80233a5
coala for the corresponding file as outputThis section revolved around bringing the output from coala to the python-QT widget.
Relevant commits: c706485
Tree component.This part involved matching the outputs from the previous section to reflect the actual desirable end result that the user will see.
Relevant commits: 249e2b4 | 0c8dbb3 | a824316
Got rid of some the messy stuff in my code although it still needs work.
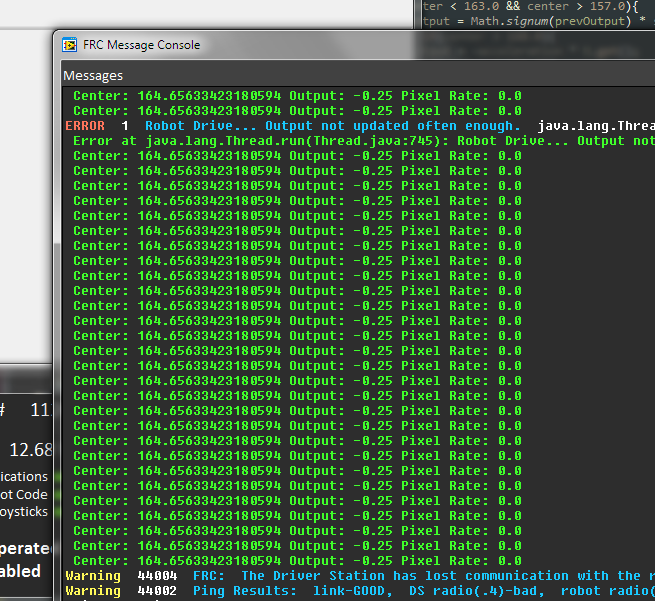
The obvious first question that arises is why? Why log your robot debug info to a USB drive instead of to the console or to the roboRIO? Well, as it turns out, there are many benefits to storing your logs on an easily removable drive which could make debugging problems at competitions significantly smoother for your team. In this article, I’ll be detailing the good, the bad and the ugly as it relates to this type of logging.
When logging to the console, you have very little input as to how your data is logged. It comes out as a string, and the contents of that string are about as much as you’re able to control. Sure you could add a timestamp or a log level, but graphing that data or using it in any other programs would likely be a pretty big pain.
This year, our team used badlog (thanks team 1014!) to save our data in a CSV format which, when used with the accompanying badlogvis, can output some pretty extraordinary looking visualizations of your logs from the match.
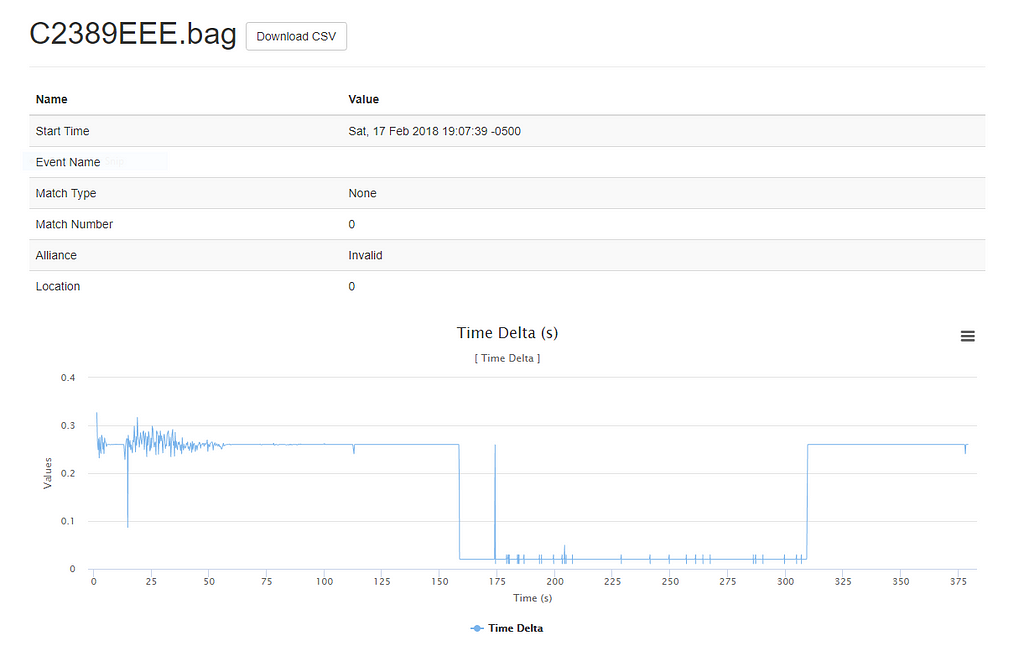
In comparison to having to power up the robot and SSH into the roboRIO every time you want to download a log file, pulling out a thumb drive and plugging it into your computer is pretty painless. It allows for quicker access to the critical log information that needs to be seen and processed before the next match. There were certainly a fair number of matches over the past season where I unplugged the drive as soon as I was able to get on the field, and quickly fled to the dark corner of the pit with my laptop to process the data before the robot even arrived. In total, having a USB drive likely saved our team at least a few hours of booting up the robot, SSHing in and downloading the latest log file.
Numerous people on ChiefDelphi have reported lag due to a large number of console logs flooding the network. Luckily, since your files are stored on a USB drive and never sent over the network, you can rest easy knowing your logging won’t cause any additional network latency.
This could have simply been an issue with how we implemented our logging (or the format of the drive) but on occasion, it would show up as corrupt when being plugged in to our computers in order to process the data. Luckily, the Windows automatic repair always took care of the issue for us, but it was still a little off-putting every time the corruption happened.
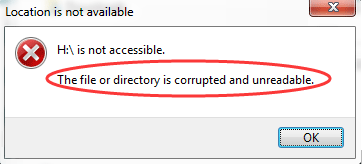
One definite way we found to reduce the likelihood of corrupt USB drives is to turn off the robot before unplugging the drive, though, unfortunately, that still didn’t entirely solve the problem.
Corrupt log files usually occur when the robot is turned off in the middle of writing a log. It’s more common than you might imagine (especially if you’re logging at a fairly high frequency, as we were), but thankfully, due to badlog’s design, the log files typically only require a minimal amount of work in order to become usable again. Still, this issue would not occur if you were only logging your data to the console.
This mainly depends on the number of logs you have and the frequency at which you’re logging. Writing to a disk (even if it’s not the roboRIO disk) can eat up a fair amount of CPU, so if you’re doing CPU intensive things on your roboRIO, such as vision processing, you might consider logging fewer things, or at a slower rate.
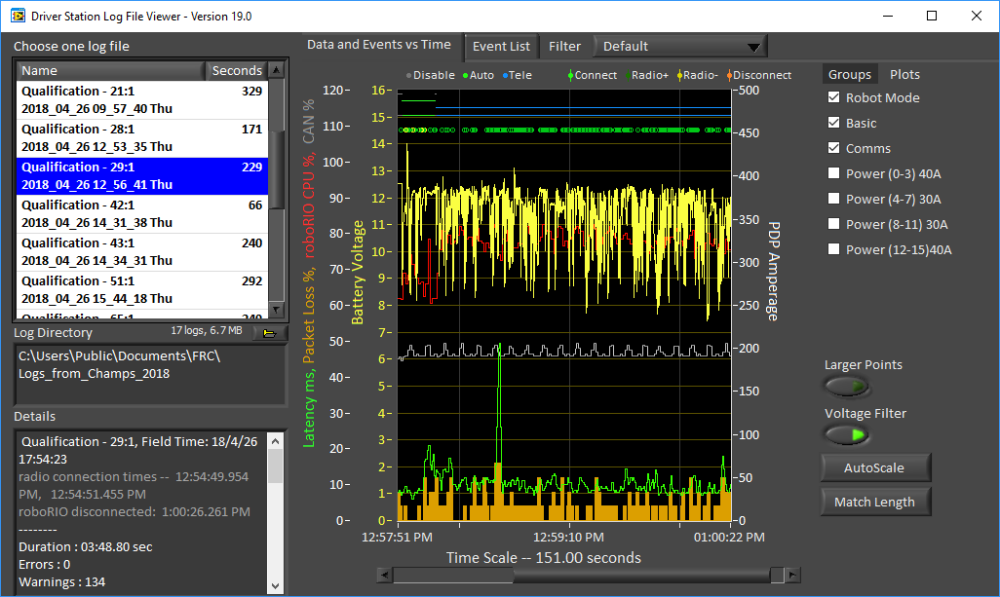
With external drives, there’s always the possibility that it come unplugged at some point before or during the match causing important logs to be lost. Thankfully this only happened once or twice during the season. The more common situation, though, was forgetting to plug the drive back in after processing the logs. In hindsight, this issue likely could have been mitigated by using the roboRIO as a backup place to store logs if the USB drive was disconnected, but we never got around to implementing that code, and it wouldn’t have fixed the drive coming unplugged mid-match.
So, with all this said, should you start logging all-out to a USB thumb drive instead of to the roboRIO or the console? Potentially, but probably not. In reality and in the heat of competition, things happen: drives are left unplugged or come loose after a hard hit, files get corrupt, or the entire USB port on the roboRIO falls out (unfortunately that last one is a little too real for us). Therefore, combining all three options and adding fallbacks where necessary will greatly increase your chance of having reliable, complete and useful logs at the end of each match.
If you’re interested in seeing an implementation of badlog in Kotlin, you can check out our 2019 code here. If you’re a Java team, team 1014 (the Bad Robots, also the authors of badlog) have their 2019 code available here.
Logging FRC robot data to a USB thumb drive was originally published in South Eugene Robotics Team on Medium, where people are continuing the conversation by highlighting and responding to this story.

Our team loves to be in control of everything that happens on the robot, from basic code to the vision system running on our coprocessor. Being in control of everything in the vision pipeline removes a majority of the trust that you need to have in other peoples’ code working reliably, while also teaching the team a lot about a vast range of topics. This desire for control is one of the primary reasons we’ve repeatedly decided not to get a Limelight. No ability to SSH in and poke around and no open source repository of the code running on the system means that we have no way to change anything to fit our use case or audit the code for possible bugs. Essentially, this left us with one option: using our own vision code, which we’ve been doing with varying degrees of success since 2016.
Being in full control introduces a fairly significant issue, too: you need to be able to trust your own code, or have monitoring systems in place to help debug any potential problems. This year, we decided to introduce a new system to help monitor the status of our vision pipeline in the form of a small, 5 inch screen on the side of our robot with color-coded status messages about the varying systems.

The screen (attached to our coproccessor, a Jetson TX1) monitors four different systems and fail-points: radio connection (ping 10.25.21.1), robot connection (ping 10.25.21.2), network table connection, and whether the vision program is actually running. If any of these systems is down or not functioning, the status message will be updated and colors changed accordingly.
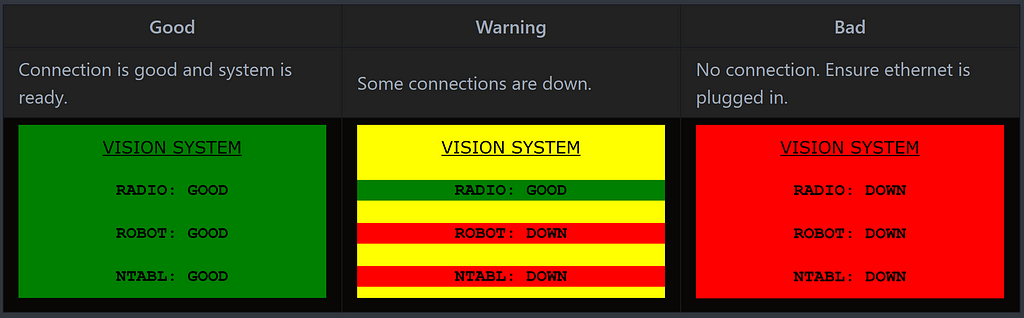
Having this fancy screen on the side of our robot helped immensely in debugging problems with our robot and vision system. While we didn’t record the exact number of times it was used, I can specifically remember at least a dozen times in which the screen was used to fix problems in the vision software or its communication with the roboRIO, including a few times on the field before a match.
And it didn’t just help us in debugging. Having the colorful (or rather, hopefully all green) status screen displayed prominently on the side of our robot drew the attention of a few big name teams and judges alike who contacted us to ask more about it. It even helped us win the Autonomous Award at one of our events!
The code for the status screen was written with appJar, a super simple GUI library for Python. If you’re interested in checking out the code, contributing, or using it for yourself, it’s all available in our vision repository, here.
How we made our vision system almost 100% reliable, without a Limelight was originally published in South Eugene Robotics Team on Medium, where people are continuing the conversation by highlighting and responding to this story.
With the help of my mentor, John the direction of my project is more concrete now.
Spyder is a scientific IDE which I have used in some of my other projects. Although it does have a core-maintained
plugin for pylint, the plethora of bears provided by
coala would be a welcome addition. To achieve this, the following needs to be done:
First off, to introduce the difference between plugins in spyder from the ones in text editors like vim and sublime-text,
plugins in the latter category are external packages that interface with the editor through a certain set of APIs.
In Spyder, plugins are first-class modules that can do almost anything that the built-in ones
(Editor, Console, Static Code Analysis, Profiler, etc) can, since the built-in ones are actually structured as plugins
themselves. This also leads to a drawback - in spyder the plugins can’t be reloaded the same way without actually
terminating the python instance. This isn’t good news for actually testing the plugin. To resolve this issue, plugins are
structured as standalone GUI widgets which can be launched, modified and tested separately. . So, depending on what
we want to test, we can usually just launch the plugin without the whole Spyder mainwindow (which can be done almost
instantly). Only when we actually need to test the interaction with the Spyder GUI, do we need to actually launch spyder
entirely. Also another resolution to this is by mocking in unit-tests.
The file-hierarchy of the coala-spyder plugin is structured as:
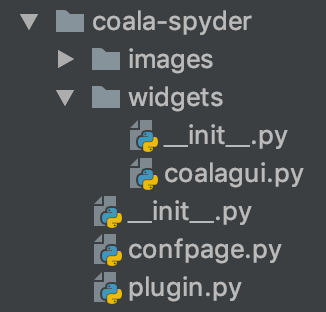
where coalagui.py will contain the independent widget which can be tested as a stand-alone entity. confpage.py will
contain configuration options and plugin.py interfaces our widget with the spyder ide.
The way that coala can interface with the plugin is directly through python as a module using
coalib.coala, although for a more immediate response we
can use the work of another two other contributors to coala, Boxuan Li and
Ce Gao. The usefulness lies in invoking coala on a specific file instead of the entire
project. This also means faster and useful results delivered to the user.
More on details of testing and continuous integration in future posts, but briefly, we can use pytest and circleci
to deal with it.
Jupyter lab is something new to me, although I have used jupyter
notebooks extensively in projects. It also paves the way for coala to be integrated in another scientific environment.
In this case, the plugin itself will be written using typscript and python. The former of which I have not tried
before but I am keen on using. I’ll leave this section short as there’s a lot I need to learn about before diving into
specifics which I plan to do partially before and during phase-1.
I plan on leaving this phase for maintenance or things left out in the previous two phases (if nothing, maybe including more features) or other work that can be done on other text editors. More on this later too.
Had a quick chat with my mentor, John. We dived into things that need to be done pretty quickly. Key points from our conversation which are relevant to this project were:
1) Existing work on Language Server (per keystroke diagnosis) by an existing GSoC student. Where he handled a lot of work in “shelling out” coala so that coala doesn’t run on the entire project but only on specified files is an integral part which will prove to be useful for me. Touching bases with the author and looking into this project is definetly something I should do.
2) A desire to re-evaluate my current choice of editors for which maintained plugins will be made. Prior to the conversation, I was keen on focussing on just basic vim, atom and sublime-text. It quickly became apparent that although it may satisfy the requirements for the completion of this project, practically it doesn’t seem to be too desirable. Editors like spyder are widely being used when working with practical recent developments in machine learning alongside other pythonic development environments like pycharm. Also, different forks of vi/vim (neovim, vim8) could probably have a single plugin with minimal modifications required to get things working.
3) Continuous-integration using opensuse vs debian build-system. I’ll have to look into this as it’s something that I haven’t worked with before before I write up on it.
Conclusions revolved around having multiple editors in a single repository if it’s a possibility which was a part of my initial proposal, getting testing modules working and figuring out ways I could combine this project with other work I’m currently doing.
I’ll touch bases with my mentor again on Friday, by when I should have a more concrete path of where this project is heading.
That’s all for now :)
My journey from Python to Golang via Node.js
Ever since college, I dabbled with Python, made a few scripts here and there, built some websites with Flask and Django. It was the first language I referred to anyone because it was quite easy to start with and delivers amazing results to the developers in no time. Although it was quite a break from having to program in C and Java, the language felt lacking in some of the most important areas.
Now came Node.js into my life and I began experimenting with concurrency patterns. Backend JavaScript? Who would take that seriously? At best, it seemed like a new attempt to make server-side development easier at the cost of performance, scalability, etc. Maybe it’s just my ingrained developer skepticism, but there’s always been that alarm that goes off in my brain when I read about something being fast and easy and production-level.
Node.js became my go to language for a very long time. I got used to the latest programming syntaxes with using ES7 in the client side of things. The single threaded node event-loop made miracles possible for me, without severing any kind of performance and being cheap to use. As time passed, I began a deeper dive into the world of npm modules and the architecture of Node.js. It is a magical space filled with unicorns and rainbows.
Most developers have heard about Node’s non-blocking I/O model; it’s great because it means all requests are handled asynchronously without blocking execution, or incurring any overhead (like with threads and processes) and as the developer you can be blissfully unaware what’s happening in the backend. However, it’s always important to keep in mind that Node is single-threaded which means none of your code runs in parallel. I/O may not block the server but your code certainly does. If you call sleep for 5 seconds, your server will be unresponsive during that time. But my actual problem came with JavaScript. I know most of you will feel this like a rant and there are ways to solve this problem. Please, just bear with me through this.
When people were developing JavaScript, they wanted it to do all sorts of things and serve every other purpose. It all started with those thoughts, which made it kind of messy. Determining boolean outcomes in plain old JavaScript is hard.

// all true
1 == '1';
1 == [1];
'1' == [1];
// all false
1 === '1';
1 === [1];
'1' === [1];
The internal type system of JavaScript is a mixed bag with six different types which causes all sorts of havoc to the end user.
I know there are ways to sort out these issues effectively, but a language experiencing these sorts of mutability can be problematic to users who are new to JavaScript world.
Then comes callback hell and having to deal with Promises and all in all the new keywords async and await . I always had retrospection over my language choices and it became very clear that I need strong typing and I can’t live without it. I tried TypeScript but it seemed a bit too expressive to start with.
My main requirements for a language were speed, reliability, built-in concurrency patterns, a strong type system, garbage collection and lots of tooling. It’s not until recent times that I felt the need for all this stuff. I heard rumours earlier about Google building a new language that is going to change the world. True to the naming, it really brought about some deal breaking changes. Here’s a list of things I like about Go and why you’ll love it too.

Yes, it is very opinionated. But, I love the way of doing things in one way. With Golang, to do something, there’s just one way of doing it. The official tooling built around Go ensures that we do follow the one way.
The first half of Go’s concurrency paradigms. Lightweight, concurrent function execution. You can spawn tons of these if needed and the Go runtime multiplexes them onto the configured number of CPUs/Threads as needed. They start with a super small stack that can grow (and shrink) via dynamic allocation (and freeing). They are as simple as go f(x), where f() is a function.

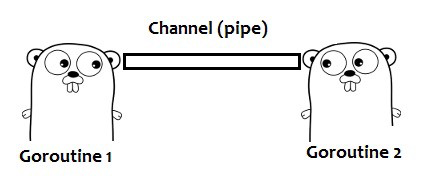
The other half of Go’s concurrency story. Channels are a typed conduit used to send and receive values. These are used to pass values to and from Goroutines for processing. They are by default unbuffered, meaning synchronous and blocking. They can also be buffered, allowing values to queue up inside of them for processing. Multiple go routines can read/write to them at the same time without having to take locks. Go also has primitives for reading from multiple channels simultaneously via the select statement.
Go compiles your program into a static binary. Yep, you heard it right. A static binary. This makes deployment really simple. Just copy the binary and it should be good to go. No pip install, no virtualenv, no freaking npm install . All of that is handled at compile time.

This is too good to be true. But it is. Yes. Golang allows cross compilation. Ever wanted to test your program on Windows but you use Linux? No more installing compilation tools and building it again on windows. Simply, use GOOS=windows and you can compile it on a Mac or a Linux machine. It even allows changing the architecture of the platform with GOARCH . There’s a laundry list of available platforms and OSes. You can find the list here.
Go is a complied language, but still has a runtime. It handles all of the details of mallocing memory for you, allocating/deallocating space for variables, etc. Memory used by variables lasts as long as the variables are referenced, which is usually the scope of a function. Go has a garbage collector.
“For the love of all holy Mary, please don’t bring back pointers.” And, well, yeah, they almost averted the crisis in the case of Golang. Everything is passed by value, but there are pointers. It’s just that the value of a pointer is a memory location, so it acts as pass by reference. This means that, by default, there is no shared state between functions. But, you can pass a pointer if you desire/need it for performance/memory utilization reasons. Go does the right thing by default, but doesn’t shackle you. Oh, and there isn’t any pointer math, so you won’t screw yourself with it. As pointed out on HN, you can do pointer math with the “unsafe” package and unsafe.Pointer.
Go has structs and interfaces. Go’s structs can have methods associated with them. Structs can be anonymously included in other structs to make the inside struct’s variables/methods available as part of the enclosting struct. Interfaces are sets of method signatures. Structs implement an interface by implementing the methods described by the interface definition. Functions can receive values by interface, like so. The compiler checks all of this at compile time.
Or lack there of. Since Go compiles everything statically, you don’t have to worry about packages at runtime. But how do you include libraries into your code? Simply by importing them via url, like so: import "github.com/bmizerany/pq". Go’s tooling knows how to look that up and clone the repo. Also works with Mercurial, Bazaar & Subversion. go get it, my boy.
Go supports anonymous functions that can form closures. These functions can then be passed around and retain the environment under which they were created, like so. This can be super powerful when combined with channels and go routines.
It supports pprof as a part of the standard library. And with a very small bit of work, you can access profiling info via a http interface.

Ever forget to close a file descriptor or free some memory? So have the designers of Go. The reason for this is that you usually have to perform those actions far away from where the resources were opened/allocated. Go solves this problem with the defer statement. Each defer statement pushes a function/expression onto a stack that get’s executed in LIFO order after the enclosing function returns. This makes cleanup really easy, after opened a file, just defer file.Close().
Go’s standard library is pretty comprehensive.
Go compiles down to native code and it does it fast. Usually in just a few seconds. No matter if you have a million package imports. It does compile in seconds. There’s a rumour that Golang actually came to life over a discussion developers had during a code compilation break.
Go do a go --help. Some of my favorites: go fmt, go doc, go fix go get go tool pprof& go test.
Super straight foward, no magic. And hell, yeah, it even has a race detector that finds out all your runtime woes even before hitting production.
By using build directives you can integrate with C libraries really easily.
The syntax is pretty simple, C like w/o all the crazy of C. But what’s really nice is go fmt, which re-writes your code into the Go standard format. No more arguments like tabs vs spaces or indentation rules! There’s just one way and you have to stick to it my friend.
With all of that said, it’s not perfect…
Go’s runtime is not super tuned yet. By comparison the JVM has had over 18 years of development history behind it. But, for a 1.0.X runtime & language, Go is pretty damn good.
Go programs can malloc a lot of ram at times, even when the program itself isn’t using much. Most of this shows up as VIRT though, so most linux systems just won’t care.
This is going to change over time, but the runtime will, by default, use only one CPU.
I can bear with having a few cons. After all nothing is perfect in this world. I can live by knowing that there are a few disadvantages while using a language as long as they don’t affect programming like JavaScript’s falsity or callback hell.
The Gopher way was originally published in My New Roots.. on Medium, where people are continuing the conversation by highlighting and responding to this story.
A short story on how things changed.
2017 was a massive year in my life as a developer. It brought about no small changes both in how I go about writing code as well as how I interact with other developers. The one thing that “mattered the most” is collaboration. 🙌 It’s not just that open source development demands a greater degree of collaboration, but the acceleration of open source as a movement on all ends during the past few years has actually redefined how software development is done. It became a highly collaborative process with distributed version control systems everywhere. 🌍

This totally changed the way I write code 💻 . To begin with, it has helped me organise my development workflow. For example, when I want to work on a bug fix or a new feature, I can branch off anytime. While Git has had an impact on how I personally write code, what has transformed software development into a truly collaborative process has been the rise of code hosting services such as GitHub, Bitbucket or Visual Studio Team Services, which provide tools for implementing a collaboration workflow based on Git, with work isolated into branches, organized into commits and documented with commit messages.
Google Summer of Code 2017 was the one major thing in my life that totally changed it. 😇 I was initially only hoping to finish up the project to 💰 gain money. Only now do I understand that money is the least of the goodies from GSoC. To start with, it gave me new friends 👬 and connections. That is the huge part of the deal. Being a GSoC alumni, you can dive into any of the GSoC summits taking place everywhere in the world. Although I haven't attended any yet, I’m planning on visiting somewhere next year. I’m so thankful to my mentors for patiently bearing with me through GSoC. Our interaction during the small period of three months brought about some of the most interesting changes in my life. I was offered a contract as a part time freelancer while still being in college. That moment when you really can pay your bills 🎉 was epic. I worked for almost an year of college and it never felt burdening as some of my friends said it would. 😏
Then comes Mozilla 🦊 into my life. 20th November 2017, marks the day we applied for Mozilla Open Source Support. We were initially so skeptical about the deal and were not sure how much our project aligns to Mozilla’s 🔐 privacy guidelines. Our product wasn’t much focused on privacy, so we had our doubts. We waited patiently through the first couple of months and then lost our hope gradually. But, miraculously, 😍 they reached out to us after five months with the news that I was awarded with the Mozilla Open Source Support Award 2017. By the time I was aware of the news, our project was halfway done. This really eased things up for me. Although the total period of the project was a whopping 12 months, we finished it up in almost half the time thanks to my enthusiastic mentors.
I never attended a college placement as I wasn’t keen on doing a full time job and wanted to continue as a freelancer. I also have plans for higher studies, so I didn’t want to pull myself into job woes 😩. Initially, I regretted my decision for not attending on-campus placements soon after I left college. Almost all of my friends were busy starting their new lives at companies. It felt so lonely and disturbing. That was the moment I decided to go full out on the search for a job. With about two years of open source record on my resume, it wasn’t that difficult to gain a job in the world outside of placements. I was contacted by atleast 20 companies in the span of a month and I started making choices. I attended 3 interviews and got selected 💃 in two of them. By the end of the month, I had two opportunities to choose from. Then, came my saviour, ❤️Lasse, one of my mentors from GSoC. He brought to me another opportunity to work with a community of people I’ve already known from GSoC. Imagine how refreshing 😍 it would feel to continue working with people whom you already love to work with. I dished out all other options and went with my mentor. I never had the thought that landing a job would be this effortless, provided you have good connections. And a GSoC really helped me get those good connections. I kind of hoped that “making choices” part would come to my life at some point. But, I never knew that it would be so early in life. (I am still 20 😁)

I hope your journey into open source would be as enriching for you as it has been for me.
How Open Source turned my Life Around. was originally published in My New Roots.. on Medium, where people are continuing the conversation by highlighting and responding to this story.

It can be frustrating to to hear about how to make your life wonderful by doing things that you can’t necessarily do on a daily basis because of your job or lifestyle. I hear about people travelling all time to far flung places, or spending days outside, and the only thing that I can think of is how unfair it is that I’m cooped up in my home, with the only view of outside being the screen in front of me.
However, as someone like me who likes to make the most of each day, (not just weekends!), there are a few things I do to make even my most mundane Mondays a little brighter, because I’m a big believer that every day should be made ridiculously amazing!
Yes. I know my friends. We all are insomniacs and stay up all night doing all kinds of things. But, do give it a try, an early sleep and early rise can truly fresh up your day a lot. Use the time to take a stroll down to a park or even just the sidewalk, if you don’t live near any park. Frantically running into showers, driving or walking to the office, and sitting at your desk before your body has even had time to adjust to your new day, only worsens your day. Set yourself a tone for the mellower day, instead.
Thanks to few of my colleagues, I recently started writing up to-do lists at work. It feels so refreshing at the end of the day seeing all those check marks. To give it a try, I brought the same change to my life, not just work. It just feels too good to be true, that simple things like these really refresh your day. But this trick really does work.
Halfway through your morning and through the afternoon, I force myself to standup and walk around. (Couldn’t do that earlier, so, I forced my laptop to go to sleep, if I didn’t have a walk in time.) I’m trying to do this as often as possible. This helped me have a break from all the problems at work. Work is just work to get paid. It shouldn’t be haunting your afterlife.
Be in the moment. Enjoy whatever the food you are eating. Get outside and have a walk, read a book or just take in the day for whatever amount of time you can spare.
This helps in keeping you away from boredom. Routine way of life gets you bored easily. Don’t just come home, eat dinner and relax on the couch. We should mix things up, if anything go for a long drive out into the wilderness, have a hike planned, take your pet for a walk or visit a beach, watch some movies (the kind you have never seen before) or just have bonfires in the backyard. Just because it is “an evening in the weekdays” doesn’t mean that you can’t enjoy it!
Have something you really enjoy for each meal. Even if it it’s something cooked at home, have a change of menu everyday. And I tried cooking something on my own, didn’t turn out to be good, but it really gave me a lot of satisfaction. Plan out some fun dinner, which is both fun to make and eat! Once you start experimenting in the kitchen, it is hard to stop and the possibilities are endless!
Be thankful for everything that happened during the day. The most important thing of all these things is to practice mindfulness throughout the day. Even on your way to work, which may seem like the most mundane thing ever, take in the weather, the sounds, the sights. At work, notice the people around you, and make the best of whatever your job might be. You’re there, so may as well make the best of it and take pride in your accomplishments. Our world is always changing, every second of every hour, so make sure you witness as much of it as you can.
Hope this helps at least someone in their life. If these tricks really helped you too, take time to throw in some claps. Follow me for more such updates.
I’m bored of life. was originally published in My New Roots.. on Medium, where people are continuing the conversation by highlighting and responding to this story.
Deploy to AWS EC2 instances using GitLab CI/CD pipelines.
So, recently, I’ve been trying to deploy a private repository from GitLab CI/CD pipelines. I couldn’t find an easy way to deploy docker images to EC2 instances. So, I made a workaround of my own using a crazy simple tool we all know of, the SSH.
Through this tutorial, I’m gonna be assuming that you have a working EC2 instance with sudo access to the shell and you already have a docker-compose file ready to set off to production.
SSH into your instance and install docker and docker-compose on it. There are numerous tutorials available online on how to install them. So, I’m not gonna cover that here.
Once you’ve got them setup, choose a location to place your docker-compose.yml file. Preferably somewhere in /opt/<your_app_name> . So, now, try deploying the compose file directly using docker-compose up -d . Once you’re sure that works, let’s move on to the next step.
Generate an SSH RSA private/public key pair, that we’re going to use to login from GitLab CI runner and run the deploy script. To generate the key pair, we’ll use ssh-keygen.
$ ssh-keygen -t rsa -b 4096 -f privkey
Now, you should have two files, privkey and privkey.pub in your current working directory. Paste the contents of privkey as is (without extra spaces) into ~/.ssh/authorized_keys on the EC2 instance. Copy the contents of privkey.pub , we’ll be using that later from the gitlab CI.
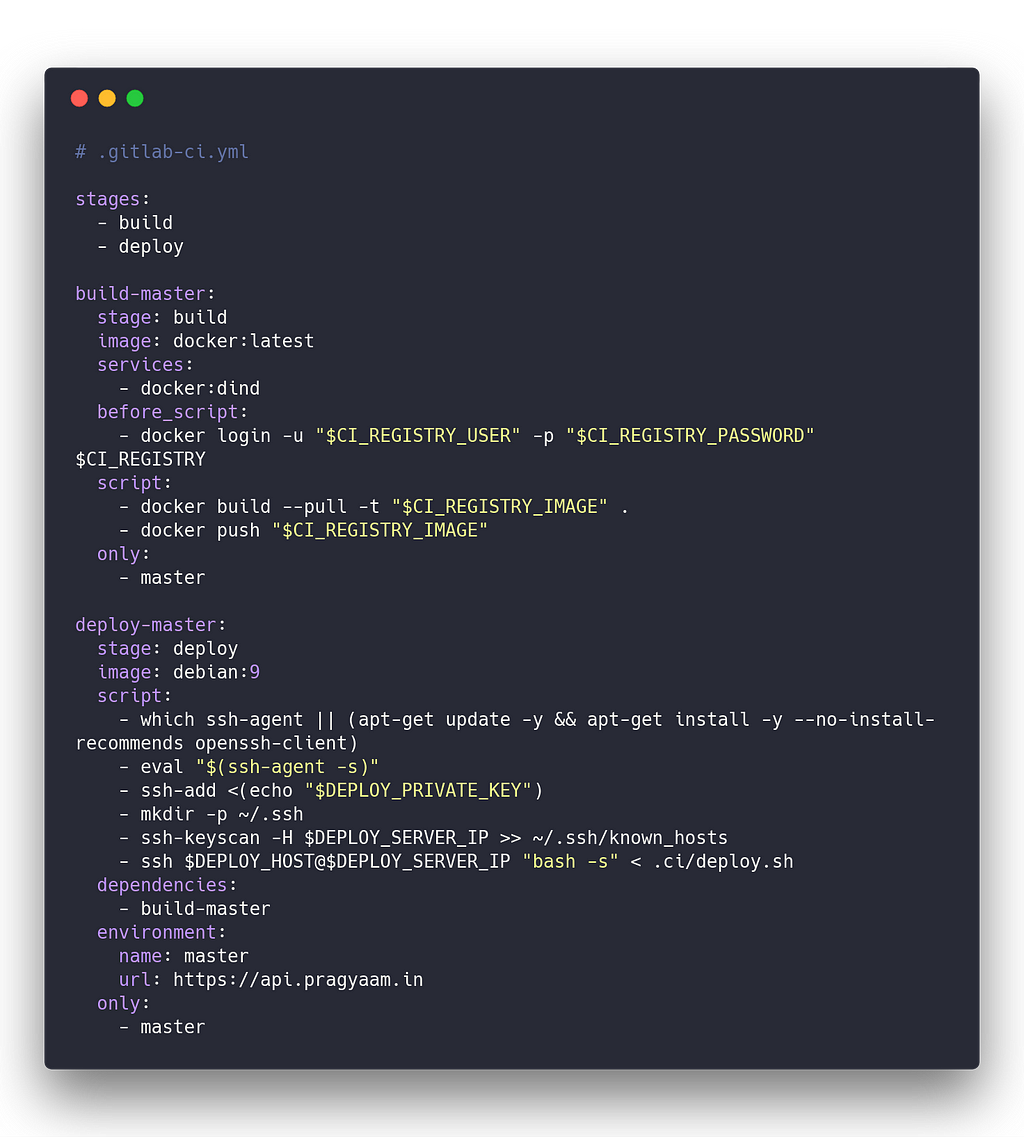
I’m gonna show an opinionated GitLab CI configuration file, which we’ll be using to build and deploy the images from master branch of the repository.
Now, we use the GitLab CI preferences pane, where we’ll setup a few environment variables listed below.
Make sure that you’ve turned on the protected flag in the variables section for each of the variables to set them only on protected branches like master.
From the GitLab CI configuration file, you can see that there is a script .ci/deploy.sh on the repository which we’ll be using to run for deployments. It can be something like this.
# .ci/deploy.sh
#!/usr/bin/env bash
set -x -e -o pipefail
COMPOSE_LOCATION="/opt/<your_app_name>/master"
DOCKER_GROUP_NAME="docker"
# Early checks
which docker
which docker-compose
id -nG | grep "$DOCKER_GROUP_NAME"
# Start deployment
cd $COMPOSE_LOCATION
docker-compose pull
docker-compose up -d
That’s it, you’re done setting up CD with GitLab.
Ship it! was originally published in My New Roots.. on Medium, where people are continuing the conversation by highlighting and responding to this story.
I had been contributing to scancode-toolkit for quite a while and it took me a few months to get accustomed to the codebase. It was the 12th February, 2018 and the list of accepted mentoring organizations was published. I booted up my laptop in excitement to give the list a glance. When I scrolled through, I was unable to find AboutCode (the organization I was contributing to) in the roll. I was devastated at the unfortunate event and spent the next few hours pondering over my endeavour since the past couple of months.
I had always dreamt of becoming a DOUBLE GSOCER and I knew it wasn’t going to be easy. This would mean I would have to reiterate the entire process, i.e. shortlist an organization and start contributing from scratch ! After a heavy setback, I decided to continue with the struggle and not give up on my aspiration. I found SPDX (Software Package Data Exchange) which is an open standard for communicating software bill of material information (including components, copyrights, and security references). I spent the next few weeks exploring the Python library to parse, validate and create SPDX documents and preparing mockups. Since the project involved lexing and parsing, I had to comprehend the fundamentals of compiler theory. Fast forward to the judgement day; I was busy refreshing the GSoC page, in the middle of the road, with my friend to check the result and here’s what it displayed:

Furthermore, I received a mail from Google confirming my selection for the paramount program.

The community bonding period is almost over with just a week remaining. I have
almost completed upgrading the Document class and initiated a few bug fixes.
I would like to heartily thank my mentors
@pombredanne and
@krysnuvadga for keeping faith in me
throughout the process and giving me the opportunity to be a part of the SPDX
community. I’m super excited to spend this summer with SPDX and intend to use
this blog to post updates and developments.
Because I am in that phase of life where I need to take one of the most important decisions of my life and it turns out that my thoughts are a chaos. Let’s compare the things I know v/s the things I don’t:
Every career related decision I had to take up until now, I never really had to sit and think. They just came naturally, take the example of:
What college do you want to go to?
I was already a student in the Aligarh Muslim University when I applied for B.Tech program - My rank elsewhere was average, so it was the only option. I like the city, my friends are here - I feel like I did no mistake.
Nope, I never even thought of pursuing higher education. With the advent of MOOC’s and the Internet, I thought that I would never need formal training. But, soon enough, I was introduced to the field of autonomous robotics and MOOC’s weren’t able to satisfy my hunger, perhaps because it requires practical/physical exposure. At this time, I just had a faint, out of nowhere idea of an MS, but I wasn’t very serious. When no one around me was getting a job I thought we can get, I started to take this idea into consideration.
When the results for the third semester were out, a month ago, before entering my name into the website, I thought to myself about planning my reaction and almost naturally, yet passionlessly, my brain spurred out that I am ready to accept whatever I had expected (~ 8 ± 0.2). There need not any “resolutions” wherein I would try working harder the next time or to attend more classes, because what I believe today “Mr. Busy effect” - I won’t be able to give time to other things I (like to) do (contribute to open source, mentor new folks in AMU-OSS, study robotics, write blog posts, read). I also thought that I ain’t learning in class anyways, so my current way of studying (don’t ever open your book in regular days and cram everything the night before the test) was the “optimum” choice.
Ready for results, with absolutely no enthusiasm, I entered my credentials into the website and kept staring at it. I was trying to calculate how precarious life can turn out to be - I had scored a whooping 9.4 / 10 (my highest ever in college) and I was actually feeling happy (maybe it was shock, I’m not sure). The next few moments, I critically examined my result only to find out that I have got a few A’s in the subjects I thought I never would and quite ironically I also scored a B in a subject I thought I never would! ;-) I had “my moment” then and there, but soon everything faded away in the color of life.
Not until, I had started preparing myself for this (4th) semester’s mid-term tests, I realized that somewhere inside me, I had started to feel that I want to score high again, I want to study for exams - What if I scored low again? - What about MS?
This is where I started feeling confused. Can I afford an MS, would I be selected, am I too late?
Although I don’t have answers to all (or any) of my questions, it turns out that writing this blog post gave me some clarity on the situation:
Thank You for reading! - I’d highly appreciate your advice!
During PyCon India, I had the privilege to meet Sanyam (@CuriousLeaner), whom I already knew as a mentor to many in the #dgplug community, when he visited the coala community space. We had a short discussion about How to nurture Open Source Communities in college? It was then, when @crancg got him to join the slack for AMU-OSS. And then, one wild day we invited Sanyam to come speak at our college and share his insights on OSS and the following event was born.

The first part of the session consisted of an introduction to the concept of Free and Open Source Software, and was chaired by Sanyam - the students were made aware of the importance of FOSS in the world. He and the other mentors also took questions and cleared the doubts of students regarding the world of open source.
The second part of the session was a hands-on technical event, and the students were taught how to implement an add-on (extension) for Mozilla Firefox. The importance of extensions for adding functionality to any browser was stressed, and the students were encouraged to build their own add-ons and to get them published.
The final part of the event involved the mentors explaining how students could contribute to open source, and how the community was always looking to better itself through the contributions of new and young talent. The talk was inspirational and the students in attendance seemed motivated and encouraged to become a part of the development community.
First of all, I would like to thank Sanyam, Shashank and Shivam for coming to the event and inspiring students. A huge shoutout to @crancg for having established AMU-OSS. I would also like to express my gratitude towards Mr. Zafaryab Sir, who is always enthusiastic about such initiatives without whom the event would never have been possible. Also, a special thanks to Areeb Bhai and Omar Bhai for providing me guidance throughout.
Team Members:
Camera Team:
and the whole team of AMU-OSS
Thank You so much!

Over the past few years I’ve become an avid supporter of FOSS and the open-source community, and it became a goal of mine to start contributing to the open-source world. Google Code-In seemed like the perfect opportunity to help me achieve this goal (and much sooner than I thought!), so I signed up without hesitation.
Once the contest began, I had to choose my first task. I picked a task from coala because, well, I thought “coala” was a cute name. coala is a handy tool that can lint and often fix problems in your source code. They have a very helpful guide for newcomers too, making it easy for anyone to get started with contributing.
My first task was a coding task, but the process of using git and creating tests proved far tougher than writing the main piece of code. I made a lot of mistakes in these areas, and didn’t do things quite the way I should have been doing them, but with some help from my mentors my work was eventually merged, and I had made my first contribution. Success!
Almost a month later, and I’ve completed an array of different tasks and learnt a ton of new stuff. School, exams and other priorities meant I couldn’t dedicate as much time as I would have liked to Code-In, but I made sure to attempt a variety of different tasks in different areas. Naturally, I encountered difficulties on almost every task — there was a lot of time spent meticulously reading through source code in an attempt to understand things, and I lost count of the number of times I had to ask for extensions. These difficulties are of course key to improving and amongst other things, I’ve finally got the hang of git, I’ve dabbled with graphics and regex for the first time, and (after several run-ins with coala’s linting bears) I’ve learnt to write cleaner and better code.
But I think the most important things I have learnt come from the experience of working within a real-life organisation. The process I had to go through in order to understand and build upon existing code taught me a lot, and using various tools to complete my tasks has given me valuable practical skills and knowledge that will no doubt be helpful in the future.
I’m incredibly grateful to the mentors at coala for providing very detailed and justified feedback where necessary, answering questions and helping me to resolve any problems. Working with such knowledgeable and friendly people has been extremely rewarding, and I hope to continue contributing to the organisation.
Finally, I’d like to thank Google for making this wonderful experience possible. I’m a little sad that I didn’t find out about GCI sooner as I’ll be too old to participate again next year, but nonetheless, I have had a lot of fun and look forward to diving deeper into the world of OSS!
Good bye crappy config files!

I’m trying out Parcel.js for one of my most recent endeavours and I must say I’m quite loving it so far. Well, as you know everyone loves webpack and brunch. But, this baby 👶 gives a rock solid support for simple things whenever you want it.
I gotta admit, the zero-config stuff is really enticing. Especially, when you’re just getting started with JavaScript and web development in general. It has built in asset packaging and hot module reloading.
But, it really is only as powerful as the config-less aproach is. For medium and large scale projects, as everyone would speak out, going for brunch or webpack is the better idea.
$ yarn global add parcel-bundler
However, getting started with parceljs is as simple as installing parceljs bundler and writing an index page with some javascript.
index.html
<html>
<body>
<script src="./index.js"></script>
</body>
</html>
index.js
console.log('Welcome to parcel.js');Parcel has a development server built in, which will automatically rebuild your app as you change files and supports hot module replacement for fast development. Just point it at your entry file:
parcel index.html
Now open http://localhost:1234/ in your browser. You can also override the default port with the -p <port number> option.
Use the development server when you don’t have your own server, or your app is entirely client rendered. If you do have your own server, you can run Parcel in watch mode instead. This still automatically rebuilds as files change and supports hot module replacement, but doesn't start a web server.
parcel watch index.html
When you’re ready to build for production, the build mode turns off watching and only builds once. See the Production 🚀 section for more details.
Boilerplates are fun, right?! was originally published in My New Roots.. on Medium, where people are continuing the conversation by highlighting and responding to this story.
So sometime ago i added a foreign key column as a rails migration which creates an index on that column as well: through the add_foreign_key method. This index is of the form rails_fk_some_hex Unfortunately i forgot to add a unique constraint with the index which was a necessary use case.
I thought ‘no big deal’ i’ll just add that now, i ran:
add_index :table_name, :column_name, unique: true, index_name: :some_name
and viola it worked on my local machine like a charm. It even removed the previous index on that column that the foreign key migration created.
but running this on staging. I had 2 indexes, 1 unique and 1 non unique -_- .
Little debugging and i could confirm a pattern:
If these 2 migrations occur in the same rails db:migrate then the add_index migration also overwrites the index created by the foreign_key migration. However in different migrations, it just adds another index.
Solution:
I’m not sure if this is a feature or a bug. To solve for the cases where migrations run together(dev machines) or on servers where they are run separately I used remove_index if index_exists? .
Conclusion:
This isn’t something “breaking or a huge discovery”, just something weird i found in my Rails Journey and something you should be aware about.
I’ve asked myself (and Google) this question numerous times and have always learned something new in the process which in turn has lead to a superficial learning of autonomous technology — helping me getting a taste of it, but for a deeper knowledge on the subject, I must complete courseware, develop some projects for hands on experience and in the process network with people who have seasoned this art who can help me get a better insight on the current trends in research and industry.

I’ve completed my home work of figuring out a Coursework for conquering the world of Self Driving Cars:
I haven’t included the Udacity self driving car Nanodegree program (although, it is a great resource) because it is quite expensive. Every course listed here is either freely available or can be audited free of cost as of January, 2018.
This is actually the most exciting and important part, as not only do I gain hands on experience on how things work here and the workflow involved, but it also allows me to build a portfolio around automotive technology which, I can then showcase to the potential employers.
It is important to take note of the fact that laying down a clear goal of a project before you start it yields better results and agreeably, it’s easy to track progress if you quantify things. For example, if your todo list currently says - go on morning walk, a yet more effective way of saying this would be - Within 30 minutes of waking up, walk 1.5 kms. Therefore, I’ll try to be as clear as possible when posing a project statement.
So, here’s the list of the projects I want to complete in the process:
I am pretty excited to dive in — let’s see how this would turn out to be! I’ll keep you updated with detailed reports on projects I make.

(This post was crossposted with minor modifications on medium.)
Many Open Source Project maintainers suffer from a significant overdose of GitHub notifications. Many have turned them off completely for that.
We (GitMate.io) are constantly researching about how people handle a flood of incoming issues in our aim to improve the situation by applying modern technologies to the problem. (Oh and we love free software!)
By analyzing the biggest open source repositories on GitHub (more info on the data below) we’ve seen that the contributors to any of those projects responds to only 2.3% of all issues on average. (Let a contributor be a person that commented on at least two issues which they didn’t open.)

This makes clear that for any bigger open source project, “Watching” the repository is resulting in a lot of spam for most of the people. If they don’t respond, notifying them was of no value for the discussion after all.
We can also observe that only very few project managers care for any significant portion of the issues. Only 6 of our human contributors in total care for more than every 5th issue at all. Here’s our heros:
25.05%: golang/go -> ianlancetaylor, Watching 47.48%: moby/moby -> thaJeztah, Watching 27.31%: moby/moby -> cpuguy83, Watching 36.67%: owncloud/core -> PVince81, Not watching 47.12%: saltstack/salt -> gtmanfred, Watching 25.54%: saltstack/salt -> Ch3LL, Watching
However, we do see that 29.1% (117) of all contributors (402) are still subscribed to all notifications of the repository (watching it).
Many contributors switch to polling instead of watching the main repository.
However, we still see that the main maintainers keep watching the repository: without them, it’s very easy to miss out on new issues and it’s hard to make sure that the right people take a look at the right issues in a decentralized system.
In many communities we see home grown bots arising that apply labels and sometimes assign people based on keywords. This works especially well for automatically created issues (e.g. from sentry) but is not a full solution.
We’ve tried it. Contributors started mentioning keywords consciously and it didn’t really work for user reported issues.
We wouldn’t be GitMate if we didn’t strive for more. Our data suggests that people are spending way too much time on their notifications. We’ve maintained coala.io in the past and we know that reading through all of them is impossible even for core maintainers. Static keyword based automation doesn’t seem to be enough.
Since quite a while we’re hacking on an artificial intelligence that helps you dealing with this problem by analyzing exactly what every person in your team is discussing about on GitHub or GitLab and mentioning the ones who are important for solving any new issue.
GitMate is built as a full automated triaging solution. Right now it already mentions related developers in new issues, finds duplicates, labels issues and closes old issues. It is already used by companies like ownCloud and Kiwi.comand we’re looking for more beta testers.
If you like this idea, visit GitMate.io and shoot us an email to lasse@gitmate.io :). If you find issues, file them at code.gitmate.io.
We’ve scraped data from a lot of GitHub repositories. We only wanted to look at the biggest ones (measured by scraped file size, i.e. roughly amount of text over all issues communicated). We’ve excluded ‘ZeroK-RTS/CrashReports’ because no humans seem to be operating that repository. The results refer to statistics drawn from those repositories:
We have filtered out any account with bot in the username as well as the ownclouders account which is using GitMate.
If you’re interested in more information, we can share our Jupyter Notebook and the data with you — just hit us an email to lasse@gitmate.io.
I’ve always loved programming, and doing it socially on GitHub makes things even better. Although I was already a member of several small organizations, such as GitPoint, ChaosTheBot and my local FIRST Robotics Team, this is my first experience working with a really large organizations — in my case, coala. It’s an amazing experience, so I’m incredibly grateful to Google Code-In for the opportunity.
Working with everyone at coala has been fantastic. Not only have I been introduced to a wonderful and powerful code linter (which I’ve already started to implement into my existing code bases), I’ve also learned a ton about Python, unit tests, coala’s commit guidelines and probably most importantly, how to work in a large-scale team environment.
In the Google Code-In competition, students claim bite-sized “tasks” that usually involve solving a specific bug or adding a feature to one of their organization’s projects. Before “claiming” a task (committing to work on that specific issue) it’s generally good to research how you might go about it and what kinds of external tools or resources might be able to help you. For example, before I claimed a task involving the generation of an RSS feed for one of coala’s websites, I first found an NPM module that could easily create the feed and then read the documentation thoroughly to make sure I understood the module’s usage. At that point, I felt comfortable enough with the technology to claim the task.
If you are pushing yourself, eventually, you will run into a problem while solving a task. That’s totally fine. The mentors are there to help you overcome any barriers you may come across. I’ve ran into difficulties and had questions about a task several times, but contacting the coala mentors on Zulip or Gitter was very simple, and, after they get back to me quickly, we always work out a good solution. I’m very fortunate to have a huge team of mentors at coala who are willing to provide loads of feedback for even the smallest change, too. Learning directly from professionals in the programming industry has helped me become a better developer and improve my coding habits and abilities.
If you’re interested in coala, get involved by solving some newcomer issues. Once you’re comfortable, choose tasks in the coala repositories with a higher difficulty. The difficulty system set up in coala repositories is very helpful when you’re just starting off, as all issues are given a rating from newcomer, to low, to medium, to high, and you can pick and choose the issues with a rating you’re comfortable with.
Overall, coala has given me a stronger appreciation for all open source software, developers and maintainers while also helping me improve my own programming abilities. I’m very happy to be a member of the team and look forward to continuing to work with them well after this year’s Google Code-In competition is complete. Who knows, maybe in a few years I’ll be able to mentor the next generation of coala developers in their Google Code-In journey, and hopefully help them have just as good of a time as I’ve been having.
Hello world, this is the new home for the Yuki blog(tm). Finally, I can use =org-mode= \m/.
Anyway, this new blog is now powered by Hugo. Hugo is really awesome and I find it to be an ease to setup this site :3.
The reason why I'm abandoning Pelican is because I find it to be a nuisance in a while. It's starting to feel like an abandoned, not maintained software especially when it's incompatible with Python 3.
Anyway, I've tried other generators such as Nikola, org-page, etc. I found those to be overly complicated, I mean come on! I just need a fucking program which generates a simple blog site from templates, How hard could that be?!. Nikola is probably the one that confuses me the most, the default config file is sooo long and most of them are useless. Sure, I like the idea of having multilingual posts (so my Indonesian friends can read my posts) but it's a bit of a nuisance. org-page feels absolutely broken to use, I can't even set it up correctly. Sure this can be caused by my "lack of skill", but if something at the start is already hard to setup, I might as well not use it.
So, I looked at Hugo, I didn't know it has Org mode supported natively. I googled it once and the first result is a blog post on how to do it by having pandoc converting it to markdown. Of course, I dislike the idea of using pandoc since it'll most likely kill some important syntaxes. I looked at emacs-easy-hugo and noticed it can do org-mode, at first I thought it does some conversion but nope, Hugo does the job.
Anyway, I end up setting up a new Hugo site and it was a breeze to setup! It's amazing that I met spf13 while on my GCI trip. I wish we talked more but I doubt he had any time to talk :(.
Setting up the layouts is suprsingly really easy, I haven't tried Go templates and this is my first time.
I used hugo-xmin as a reference and starting point, I ended up changing a lot of
things, I don't know if this is now mine or not, but whatever I added the
LICENSE of hugo-xmin as LICENSE-THEME.org and appended my name on top, It
should be fair I guess.
You might be asking why my website looks like this now. Well, I was inspired by The Website Obesity Crisis talk by Maciej Ceglowski. The talk was awesome and it inspired me to build stuff minimaly and keep the unnecessary stuff small. I revamped my main site into something like Vincent Canfield's site and Better Motherfucking Website.
At first, I kinda want it to look like my Emacs theme but I think not a lot of people would like having a darkish blue background and some bright colors for hyperlinks so I used Better Motherfucking Website's colors.
The blog is quite different, it's my new site's css with a lot of stuff added like tables and code which I would use a lot over time. I used Solarized Light background color since I find it to fit the site's background color.
Anyway, by any means I'm not a good frontend web developer. I usually work on the backend or even better the infrastructure/system side of things. Stuff like automating stuff and doing system administrator work. I know very little HTML/CSS and I don't want to even use JS unless necessary on this site.
With this new site, I hope I can write more posts, I already have a couple in my head and wanna restart the "Where I come from" series of posts. I think it would be better if I cover some parts of my life and hobby like School, Console Hacking, Game Hacking, UNIX stuff, etc since I do a lot of interesting stuff as a kid and it'll be a really long read if I cover all of them in one post. Instead I would start covering each part of the stuff that I wanna talk about and converge them at the end. I don't know how obviously especially with my pretty weak writing skills but I like the challenge. Hopefully by doing this "blog", I can be a better writer and be better at explaining very technical stuff to a not-so technical minded audience.
The old site is archived on my GitHub at yukiisbored/blog-archive, feel free to see my cringy early blog posts ;).
I hope I can write more posts since I really like talking about stuff I wanna talk about to an audience, I do realize I don't have a lot of readers but I don't care. At least If I need a reference for what I did in life, I have this blog which hopefully have content about interesting stuff that I did in the past or just stuff in general.
Anyway, Thanks for reading this pretty lenghty blog post <3
In the beginning, there was an organization application. And with it, the need for someone responsible. That one was me. I always wanted to help with GSoC but felt that my coding skills and codebase knowledge were not good enough to be a mentor as good as I’d like to be. So I followed the call for main admin and on the story went.
The most obvious piece of the application process is the application form every organization has to fill on the GSoC page. The problems I encountered while drafting the first version of our org profile and “Ten Reasons Why You Should Take coala”-text were essentially the same as for every application I had ever written. How does one sell themselves without making things up.
Although coala had two years of GSoC experience, those were as a sub org under the PSF umbrella. This year should be the first under our own flag, so everything had to be perfect. Again and again I asked for feedback on my drafts and input on things where I didn’t know enough about. Both Lasse and John were very helpful, both with plenty more GSoC experience than I have. We felt that we were in a pretty good position. Our community has a strong connection with the GSoC program, many of our long time members were students once upon a time. We had a total of 10 students over the two years with PSF, and from what I have heard, they were more than pleased with our performance as an organization, both the students and the PSF. The only thing that we felt went against us was us being a novice independent org, and us not having failed any of our students so far. Yup, this is a thing. From what I understood, Google expects around 20% failure rate across all organizations. If an org deviates from that too much for too long, then they are either too strict with their students, not strict enough, or there is another problem with their process. We actually were quite worried about this point but from what I have learned, there is no real reason to worry about this. Document what you and your students are doing and as long as you have good reasons for the decisions you are making, everything should be fine in the end. About the novice part, there wasn’t really anything we could do besides pointing to our past GSoC experience and hoping that Terri Oda, a PSF GSoC admin, would vouch for us.
Another, big, part of the application is the projects page. It is a list of project ideas that students can apply for. Although it is encouraged that students come up with their own project, most applications will come from the project list. And a nice project list is a must have, from what we were told, to get into GSoC. We felt that the project page should be the most well fleshed out part of our application, as it is actually useful during the following parts of the program and offers a lot of value to the students and us when the student application phase comes around. This lead to our web frontend hero Hemang building our new and awesome Project Page. Before this, we just used a GitHub wiki page with some project drafts but the new page was much easier to use, gave a better overview about the projects and it gives us the possibility to add features to it in the future. During this early phase, we included the old projects from the wiki and asked mentors and community members for other projects ideas they might be interested in mentoring. For those who haven’t read any of the project ideas on our page, the structure always is something like this: Introduction and motivation, sometimes followed by some additional information about how to solve the problem if we already had some idea about it. Then we show a time line following the GSoC 4 phase model, that holds some milestones and gives a rough idea about when to deliver the single parts. Finally, we link all additional information we have about the project, like issues or cEPs, add mentors as contact persons, and some more meta information. In addition to the project ideas the page also holds a faq section, where we started to collect questions we received again and again or just felt were important. We actually tried to let the student’s add the questions and answers to the faq themselves to include them into our process and also to make sure they actually understood our answer and thus to double check if our answer was good enough or if maybe we need a better explanation. We had close to twenty project idea drafts at this point and felt that we were more than ready to hand everything in to Google and be accepted. Before we move on to the next part, I want to point out that we also built the projects page so other orgs could use it and we have received some good feedback on it.
In February, a few weeks before the application deadline, we went to FOSSDEM with coala. We had a stand where we promoted what we did but most important, our stand was right next to the GSoC stand. A great opportunity to get feedback and ask some questions we figured, and so I walked over in a calmer minute to show Stephanie what we had so far. Starting with the projects page, she liked it a lot. She liked the idea of it and how it was structured and could help to introduce students even easier. The only improvement she asked for with it were the project descriptions. Flesh out the motivation for most projects and just write a little more to make it easier for students was what I took away for the projects age. But overall this part gave me a very good feeling!
Then we talked about our chances to get into the program with the experience we had under our belt and our expectations and wishes for slots we would get. As I said before, we had 10 students over the last two seasons. First 2, then 8. We felt, that we could probably grow some more with the mentor power we had amassed but also didn’t expect too much as we had some challenges coming up, that we didn’t have the last two times. What I asked was probably something along the lines of “how high are our chances to get around 12 students this year with what I just showed you + improvements I’ll implement?”. And here is where the not-so-fun part started. She essentially looked at me as if I asked for a million dollars out of nowhere. Turns out, that first time organizations usually get 1 or 2 students. And even with our past experience as a sub org, we kind of counted as a first time org. I pointed out that we had 8 students under PSF last year and received great feedback from their admins for our work and Stephanie couldn’t believe that we did get such an enormous number of students as such a young org. I came out of that part of our conversation with the feeling that we’d probably not get more than 4 slots no matter what we did. Not a great takeaway.
I rewrote a lot of our application texts to focus more on the things Stephanie pointed out as important factors after we returned but the main part of work I did was essentially rewriting all twenty something project proposals we had. Although I wrote some of them myself, most of them were actually written by students or mentors and I did all the review work. The reason or this was that even though I probably would have been faster just writing everything myself, I wouldn’t be able to get enough reviews to merge everything in time. So the solution was to poke students that were interested in the projects and mentors to rewrite it and me reviewing it.
During this time I also struggled with the expected slots we would get. While yes, we would finally be our own organization, with all the pros that would bring with it long term, it also felt like a step backwards to loose students slots compared to last year. But the fact that we couldn’t grow further under the PSF and had plans to act as an umbrella for smaller linter projects made the investment in our long term growth worth it in our eyes. I should probably add that we had more than 5 newcomers per week during this time that were interested in GSoC with us. This meant that the newcomers from one week might be more than we would get. And there were quite some students that came to us end of last year and had contributed a lot. Hard time deciding whom to take on the horizon already.
After completing the projects rewrite we called it done and handed everything in for the final time. Now all that was left was to wait and get to know the possible students.
We were accepted. And although it doesn’t quite fit here chronologically, we received 10 slots. We were happy when we were accepted and a huge weight left my shoulders. But the real joy came when we received those 10 slots. Apparently Terri gave us one hell of a recommendation and all the mentors we had collected and project ideas we had prepared were worth something after all. John, one of the other mentors, also met Stephanie at FOSSASIA and kind of implied that getting only two slots wouldn’t work for us so maybe that also helped. Regardless of how we did it, yeay for the slots!
So what do I think about how everything went down? I feel like the projects page was a great idea and will serve us (and maybe other orgs) well in the future. There are some downsides to it in my opinion that I will cover in the next part more in depth but the main thing is that all those super defined projects left the students with nothing to think about in some cases. In the future, we will focus more on presenting the problem and why we’d like to fix it and less about the how to fix it in detail. This way we give students a chance to shine during their application phase by working on the specifics with the respective mentors and take some of the work off of us.
The part where we included students in writing the projects and faq entries on the other hand was great. It is definitely more work than just doing it yourself but it works as a first identifier for very good students. They will be happy to help defining projects, already starting to do research on it and discuss the details with possible mentors. Doing this in a more structured way will probably something we will try to do in future years.
About the meeting with Stephanie at FOSSDEM, I would recommend that to everyone! Stephanie is a lovely person and helped us a lot with her feedback I feel. She is also just nice to talk to :).
Overall I feel like this part of GSoC went pretty well and without real problems beside our panic of getting too few slots. Things won’t stay this rosy in the next phase sadly so if you want some drama and more interesting “things we could have done better” things, make sure to come back. I’m not sure when I will find the time to finish the next part as I have some university to catch up on and it takes me a good 2 hours to write one of these, at least so far, but I’ll try to keep at least a weekly schedule for this series until I am done.
Thanks again to Terri Oda from the PSF and Stephanie Taylor from Google for your support during this phase that definitely helped us to get into GSoC and learn a lot as an org.
The 2017 GSoC is over and it was awesome. We had 10 great students (Yes all of them!) and a tremendous experience for all of us.
In this series I’ll try to reflect on how the summer went from the point of view of the main admin for coala. As I both feel that reading very long blog posts is hard and that I won’t be able to write everything down in one go, I will split this up in multiple parts. How many, I don’t know at this point.
To give some perspective to the things I write, here some background about what my role and background were:
My role in this year’s Google Summer of Code for coala was being the main org admin. This meant, that I (mainly) was responsible for everything coala should deliver during those months. I had two backup admins with @sils and @jayvdb, who both were very helpful. And I want to highlight that a lot of the time when I write “I” that is actually all three of us (and sometimes also mentors). I just didn’t think about adding “me and all the lovely people that helped me” but it is what I mean most of the time. You can replace most “I”s and “me”s in this text with “we”.
As an admin, my job is not to do everything myself, but to make sure everything gets done. And, if no one else will do it, then it becomes my job. This started with the org application to the program itself. Writing the application and reviewing what input others had given, gathering information from past years and recruiting mentors. During that phase we also met Stephanie Taylor at FOSSDEM and got some feedback on our application and our newly created projects page. Again, I was responsible for all the feedback being implemented, not necessarily doing so myself.
After coala was accepted into the program, the student application phase soon opened. During this phase, my main work consisted of figuring out how we should cope with the insane amount of applications we received, building a process that would somehow be able to handle them (hint: we kind of failed with this), review applications and support mentors and students on their way to getting to know each other and writing applications. I am pretty sure that this part will get it’s own post and will probably be the largest one of them all. We learned a lot in this area this year but it wasn’t without growing pains sadly. At the end of the student application phase came the time to choose which student’s we would accept. With the process we had in place this year, I had to collect feedback from the mentors, form my own opinion about the students and in the end make the decision, which students we wanted to accept. And finally during this phase my job was to listen to all those, whose dreams I crushed by not choosing them.
When the actual part of GSoC started, I could actually start to relax a little bit. Most of the work now lay in the hands of the students, mentors and co-mentors. During this time I answered a lot of “how are we handling this thing” questions from students and mentors. I usually sent one or two mails per phase to both students and mentors, describing what they had to do during the current phase and reminding them of any upcoming deadlines. If any questions or problems came up and I felt the answer might help the other participants, I also added those things. Finally, I did some checkups on mentors and students, just to make sure that there no hidden problems or friction between anyone we didn’t know about.
The last part of GSoC (at least what I have in my head right now) were the evaluations. I will group them, as they essentially are the same every time in terms of what I had to do. I reminded the mentors in the phase starting mail that there would be evaluations and when our internal and when Google’ deadline was. Then I gave another reminder a few days before the evaluation opened, highlighting what mentors should focus on and some instructions about what those evaluations are for and about. During the evaluation phase I essentially just pinged every mentor that I felt might be running a little late and made sure that all evaluations were filled on time. In one case, by filling it myself. More about that when we arrive in that chapter.
I think that it is important to be transparent, especially in an open source project like coala and when handling something where so many people have worked on as GSoC. This is why I’d like to at least mention, that I received compensation from coala for the admin work I did. 1500€ to be precise. This was decided by a vote (c-level decision) by the coala maintainers and taken from the money coala as an organization received from Google. The amount was roughly estimated using the german (where I am from) minimum wage of 8.50€ and using 8h/week as the work hours. Make of this what you will. I just felt it noteworthy.
I guess I might use this as a final chapter to talk about the money we received, and what we plan on doing with it. And in that way also shine a light on the growing coala association
I will probably write the second part on my flight back on Tuesday so stay tuned for that.
Cheers!
The 2017 GSoC is over and it was awesome. We had 10 great students (Yes all of them!) and a tremendous experience for all of us.
In this series I’ll try to reflect on how the summer went from the point of view of the main admin for coala. As I both feel that reading very long blog posts is hard and that I won’t be able to write everything down in one go, I will split this up in multiple parts. How many, I don’t know at this point.
To give some perspective to the things I write, here some background about what my role and background were:
My role in this year’s Google Summer of Code for coala was being the main org admin. This meant, that I (mainly) was responsible for everything coala should deliver during those months. I had two backup admins with @sils and @jayvdb, who both were very helpful. And I want to highlight that a lot of the time when I write “I” that is actually all three of us (and sometimes also mentors). I just didn’t think about adding “me and all the lovely people that helped me” but it is what I mean most of the time. You can replace most “I”s and “me”s in this text with “we”.
As an admin, my job is not to do everything myself, but to make sure everything gets done. And, if no one else will do it, then it becomes my job. This started with the org application to the program itself. Writing the application and reviewing what input others had given, gathering information from past years and recruiting mentors. During that phase we also met Stephanie Taylor at FOSSDEM and got some feedback on our application and our newly created projects page. Again, I was responsible for all the feedback being implemented, not necessarily doing so myself.
After coala was accepted into the program, the student application phase soon opened. During this phase, my main work consisted of figuring out how we should cope with the insane amount of applications we received, building a process that would somehow be able to handle them (hint: we kind of failed with this), review applications and support mentors and students on their way to getting to know each other and writing applications. I am pretty sure that this part will get it’s own post and will probably be the largest one of them all. We learned a lot in this area this year but it wasn’t without growing pains sadly. At the end of the student application phase came the time to choose which student’s we would accept. With the process we had in place this year, I had to collect feedback from the mentors, form my own opinion about the students and in the end make the decision, which students we wanted to accept. And finally during this phase my job was to listen to all those, whose dreams I crushed by not choosing them.
When the actual part of GSoC started, I could actually start to relax a little bit. Most of the work now lay in the hands of the students, mentors and co-mentors. During this time I answered a lot of “how are we handling this thing” questions from students and mentors. I usually sent one or two mails per phase to both students and mentors, describing what they had to do during the current phase and reminding them of any upcoming deadlines. If any questions or problems came up and I felt the answer might help the other participants, I also added those things. Finally, I did some checkups on mentors and students, just to make sure that there no hidden problems or friction between anyone we didn’t know about.
The last part of GSoC (at least what I have in my head right now) were the evaluations. I will group them, as they essentially are the same every time in terms of what I had to do. I reminded the mentors in the phase starting mail that there would be evaluations and when our internal and when Google’ deadline was. Then I gave another reminder a few days before the evaluation opened, highlighting what mentors should focus on and some instructions about what those evaluations are for and about. During the evaluation phase I essentially just pinged every mentor that I felt might be running a little late and made sure that all evaluations were filled on time. In one case, by filling it myself. More about that when we arrive in that chapter.
I think that it is important to be transparent, especially in an open source project like coala and when handling something where so many people have worked on as GSoC. This is why I’d like to at least mention, that I received compensation from coala for the admin work I did. 1500€ to be precise. This was decided by a vote (c-level decision) by the coala maintainers and taken from the money coala as an organization received from Google. The amount was roughly estimated using the german (where I am from) minimum wage of 8.50€ and using 8h/week as the work hours. Make of this what you will. I just felt it noteworthy.
I guess I might use this as a final chapter to talk about the money we received, and what we plan on doing with it. And in that way also shine a light on the growing coala association
I will probably write the second part on my flight back on Tuesday so stay tuned for that.
Cheers!










TMP — Tri-Month-Pack program
TMP is a challenging program similar to M2M (Month to Master) by Max Deutsch. Hereby, I shall complete four herculean 3-Month goals, designed in such a way that their progress can be numerically monitored and that they have a specific target rather than an abstract concept (like “Being able to run at 18 km/hr for 20 mins straight without break” and not “Being able to run fast”).
The four projects are as follows:
Q. Why are you doing this?
Because I am an avid learner and maintaining accountability in this way would help me avoid procrastination and ultimately help me in learning much more effectively.
Q. How did you come up with this list?
GhostRider
My dear friend A.V .I. came up with the beautiful idea of having an anonymous social network and from then onwards I have been praising the idea. I would love to see it a reality.
Schedule Visualiser
I have a habit of procrastination and find myself wasting too much time writing, analysing and drawing my routine. I always wanted to automate it.
AI Music Generation
It came up in a casual conversation with one of my friends while discussing neural networks and the idea stuck to me from then on. Also, I am learning about Machine Learning and this would be a beautiful application. ;-)
Competitive Programming
Having been contributing to open source projects for a while now have made me familiar to the process of Software Developement, but I still consider my Computer Science skills to be subpar. Competitive Programming provides a great way to ensure that I keep on track.
Q. How much time will you be spending working on these projects?
I am an Engineering student at Zakir Hussain College of Engineering and Technology, AMU and there would be examinations, assignments, community activities, co-curricular participation nearly during every project. I also appreciate OSS development and hack actively on coala and vulture. Other than this, gym also takes up some of my time daily.
I prefer to work on these projects on leave-days and week-ends and during my free time.
Q. How do you plan to monitor your progress?
I shall monitor my progress by writing a brief journal entry in the form of a Blog Post everyday. Also, I shall keep track of what’s going on through a private gitlab repository which shall have respective milestones much like https://gitlab.com/coala/GSoC-2017.
Hi there! This is the last time I wrote here!
I hope you enjoyed my trip through GSoC 2017. It’s been an awesome journey of 3-4 months together.
Thanks to both of my mentors @Adrianzatreanu and @yukiisbored . Thank you for everything! I couldn’t think of better mentors than you guys! Also I want to Thanks to coala organization, thank you for accepting me in the GSoC program!
Finally, Thanks Google! for such a wonderful program!
With my project Improve the coala CLI I solved bugs, add new functionalities and change the aspect of the output for the user.
This is the latest ouput for the user.
Bugs were solved, now the --no-color flag works properly.
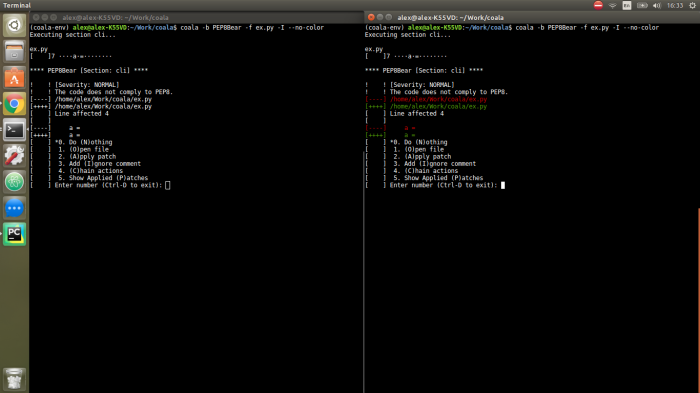
Bug with colors for different terminals. (This is LXTerminal)
Right now Do (N)othing is an action because of a6c376f.
Chain Actions is right now by default. You can now apply multiple actions in a single input 0911078.
Apply single actions was added. You can use flag -A and choose an action to apply for every result 65feb30.
Show applied actions print the latest actions that a user has done in a run of coala 149d59d.
Generate patch action generates a patch for a file based on bears depending on what language did you used in the file 25e019c.
In coala repository:
d75d10a Change output for user.
3e590f5 Change the coafile warning/output
2f0f311 Change the actions name
8a25983 Change the input: Numbers to letters
0eb0be9 Fix the ouput
45a7369 Add Chain Action
65feb30 Add apply-single-action
149d59d Add Show Applied Action
0911078 Make Chain Action default
360a624 Add line number for the diff ouput
2bd16a5 Change Severity line from the ouput
377585d Add line number inside “[ ]” in diffs
530bcd7 Rename DoNothinActionTest.py
fbb71a1 Add docs for apply single action
d03303c Fix color from the ouput
a6c376f Add Do (N)othing action
f43bd5e Fix --no-color flag
25e019c Add Action: Generate Patches
With this project we’ve tried to improve the user experience of coala in CLI. Many hours were spend trying to improve the design of it and we hope it’s better. Of course, anything can be improved over and over again.
I worked just in coala repository from github. Most of the work was done in ConsoleInteraction.py file were I did major changes. Other changes were made by adding new files for every new action and tests for all of them.
I think that the most dificult think was to have 100% coverage from tests. Also I tried to wrote good, clean code that new people could understand it.
It was an amazing trip. I think I learned how to write better code, write better tests. Also I learned how to write a proper, complex review for prs. I’ll continue working under coala and trying to help were I can.
The coding period is over and this blog post summarizes the work done by me during the short span of 2 months(June 1 - August 23). I would like to express my gratitude to coala for giving me the opportunity to work on this project and my mentor @Makman2. A big shoutout to Google for promoting the OSS (Open Source Software) culture.
The coolest part was that I could actually run the InvalidLinkBear to make sure that all the links were working.
The milestones achieved were :
generate_orderinggenerate_eq or generate_orderingRubocopBeargenerate_eq or generate_ordering with a new fieldStylintBearStylintBear supported from the coala sidestylint to dockerTextLintBearremark-lint to report useful messagesremark-validate-links pluginmarkdown_horizontal_ruleTravisLintBearPugLintBearArtisticStyleBearcheck_order=False from check_line_result_countpragma: no cover from ElmLintBearnew_process_output(...)LocalBearTestHelperHttpoliceBearCSSCombBearHTMLHintBear| Issue reference | Pull Request | Commit shortlog | Commit hash | Status |
|---|---|---|---|---|
| #754 | #1610 | bears/stylus: Add StylintBear | 47d3956 | Merged |
| #1795 | #1796 | StylintBear: Implement settings | e4a9d34 | Merged |
| #1839 | #1841 | RubocopBear: Optional generation of config_file |
45dfb62 | Merged |
| #1576 | #1597 | bears/general: Add TextLintBear | d09c8f9 | Merged |
| #294 | #1879 | bears/yaml: Add TravisLintBear | 2f004bc | Merged |
| #1548 | #1890 | RuboCopBear: Fix CI breakage for version > 0.47.1 | d35b120 | Merged |
| #1907 | #1908 | MarkdownBear: Replace markdown_horizontal_rule |
e2cf115 | Merged |
| #924 | #1919 | MarkdownBear: Add validate-links plugin |
f68bd91 | Merged |
| - | #1919 | MarkdownBear: Rename test classname | 2a21048 | Merged |
| - | #1919 | MarkdownBear: Rename remark_configs_plugins |
d83fe5f | Merged |
| - | #1919 | MarkdownBear: Improve result message | 71f6bc5 | Merged |
| - | #1919 | MarkdownBear: Rename remark_configs_settings |
d6100ce | Merged |
| #290 | #1936 | bears/pug: Add PugLintBear | 1d31827 | Merged |
| #388 | #1882 | bears/c_languages: Add ArtisticStyleBear | 65d6304 | Merged |
| #926 | #1942 | MarkdownBear: Add remark-lint settings |
3dc08bf | Merged |
| - | #1958 | requirements.txt: Update coala | 04f490c | Merged |
| #634 | #1957 | bears/css: Add CSSCombBear | 2bef3df | Merged |
| #596 | #1962 | bears/hypertext: Add HTTPoliceLintBear.py | 40dd5d4 | Merged |
| #635 | #1987 | bears/hypertext: Add HTMLHintBear | b49553a | Merged |
| #1996 | #1997 | ElmLintBear: Remove pragma: no cover |
0a25352 | Merged |
| #1978 | #1982 | TravisLintBear: Check for internet connection | f51e54d | Merged |
| Issue reference | Pull Request | Commit shortlog | Commit hash | Status |
|---|---|---|---|---|
| #4418 | #4417 | execute_bear: Improve AssertionError message |
0edf040 | Merged |
| #4451 | #4453 | LocalBearTestHelper: Remove check_order |
0aa077 | Merged |
| #455 | #4554 | Show stdout and stderr for linter bears |
bbb99f9 | Merged |
| #4576 | #4579 | LocalBearTestHelper: Add **process_output_kwargs | 2868324 | Merged |
| #4594 | #4595 | coalib/abstractions: Add LinterClass.py | 9f279e4 | Merged |
| #4594 | #4595 | Introduce isinstance(cls, LinterClass) |
2816dc6 | Merged |
| #4302 | #4310 | LocalBearTestHelper: Add assertObjectsEqual |
7f89dca | Approved |
| Issue reference | Pull Request | Commit shortlog | Commit hash | Status |
|---|---|---|---|---|
| #181 | #185 | Remove uninstallation of packages not installed | 79a0da1 | Merged |
| #184 | #185 | Install packages libxml2-devel and libxslt-devel | 17c883d | Merged |
| #182 | #185 | Use a lower version of node (nodejs6) | 51fb17d | Merged |
| #213 | #208 | Add dependency astyle |
ee1fbda | Merged |
Many new high quality bears along with an exhaustive documentation were merged and are usable. There were workflow improvements for developers regarding tests and bear writing. Developers will now be able to write better bears along with more robust tests. Although GSoC has ended, my contributions for OSS won’t stop. These 2 months have evolved my life and I’ve learnt so many things that would definitely help me grow as a developer.
Hey everyone! I’m back with another post regarding my GSoC journey so far. This is my final week into the GSoC and I’m really glad that I made it till the end.
First of all, here’s a list of things that have done since my previous mid-phase post.

.editorconfig values and can even detect the inconsistency.Gruntfile.js contents as well!With all that done.. I was able to complete my project in time and everyone would be satisfied with my work I guess
Here’s my final submission report: https://gist.github.com/satwikkansal/b72265a0d0ec678b9291ea8e21a398ec
There’s still a long way to go for coala-quickstart and the most important thing to watch out for is the aspects project which will simplify the things for the users to a lot extent and will eventually open us a lot of opportunity for us to show some coala-quickstart magic.
PS: Another blog-post walking through my whole GSoC journey in brief will be coming soon and I’m trying to make it an interesting one. So until next time…
So this it guys. The day I have worked for is finally here. This marks the end of my Google Summer of Code’2017. It’s been an awesome journey of 4 months.
Firstly, Thanks to both of my mentors SanketDG & NiklasMM. Thanks for everything! It’s been an awesome journey for me, I couldn’t have asked for better mentors than you guys. Secondly, Thanks to Org. admins and other mentors of coala.
Thank you guys, for not losing hope on me when I nearly failed my PHASE-2 milestone. Somewhere this was the sole reason which drived me to recover my work and complete my final milestone in time :)
Finally, Thanks Google! for such a wonderful programme.
I came across coala while surfing on the internet. Though those were the initial days where I wanted to learn only python, but my ideology is if you want to learn something then do a project on it ;)
The welcoming nature of the community thrived me to contribute towards this wonderful project. I continued to contribute in coala and in 2 weeks I was promoted to core-developer. This was the first ever experience of me contributing to an opensource community. Later I continued to contribute more and more. Although I already knew about Google Summer of Code but I wasn’t sure if I’m surely gonna try a shot. Until I started talking with some of the mentors of coala. First was NiklasMM, the project Handle Nested Programming language was sounding interesting. Meanwhile I was doing an issue with SanketDG. I came to know that he was an Ex-GSoCer at coala. So I started investigating with him about the process, reading his blogs, investing about how did he started….etc. At the end I got more interested towards Documentation Extraction and Parsing. We scheduled a skype call where he answered some of my doubts one on one.
And the rest, It all just happened ;)
Coming back to my project Documentation Extraction and Parsing, The final goal was to develop an analyzing routine at least for python and java that will find all documentation strings in a file, parse them into specific groups and check them against a specified documentation style given by the user. The functionality can be extended so that the analyzing routine provides a patch that re-formats the documentation correctly, checks for grammatical errors (like spell checking).
Specifics of DocStyleBear
DocStyleBear supports following style:
Python:
def xyz_function(param1, param2, param3):
"""
This is functions main description.
:param param1:
Param1 desc.
:param param2:
Param2 desc.
:param param3:
Param3 desc.
:return:
Nothing.
"""
return None
For further info check here.
Java:
class HelloWorld {
/**
* Returns an String that says Hello with the name argument.
*
* @param name
* the name to which to say hello
* @raises
* IOException throws IOException
* @return
* the concatenated string
*/
public String sayHello(String name) throws IOException {
return "Hello, " + name;
}
}
For further info check here.
Specifics of DocGrammarBear
DocGrammarBear should atleast be able to lint basic spell checking over: Main descriptions and Comments descriptions.
For example: If we have a malformed docstring.
def some_func(param1, param2):
"""
This is thet main descrpton.
:param param1:
This is param1 description.
:param param2
Thiss is param2 descripton.
:return:
Nothing
"""
This has incorrect spelling mistakes. The DocGrammarBear should be able to correct it.
def some_func(param1, param2):
"""
This is the main description.
:param param1:
This is param1 description.
:param param2
This is param2 description.
:return:
Nothing
"""
Now, if I see the whole evolution of DocumentationAPI in these past 4 months. There are many things which I achieved:
DocStyleBear was in Work-In-Progress mode, from past 1 year. So I took over that PR and with some quirks I was able to merge it in time.DocBaseClass fulfilled it. DocBaseClass have 3 static methods:
extract - Used for extracting documentation.process_documentation - Used to change the original instance of DocumentationComment according to the needed style.generate_diff - If desired instance of DocumentationComment is not obtained. Applies a diff.automatic_padding and docstring_type which made it possible for the DocumentationAPI to actually check the docstring_type and amend blanklines before and after the docstring according to PEP-257.
docstring_type of function should have paddings (top_padding=0, bottom_padding=0). Which means function level docstrings should never be followed by a line before or after.docstring_type of class should have paddings (top_padding=0, bottom_padding=1). Which means class level docstrings should be followed by a line below.DocGrammarBear, which used to analyze and fix basic spellings and grammar inside the descriptions of DocComments.Stretch Goal
MalformedComment which will be returned instead of DocumentationComment, if any part of DocumentationAPI(DocumentationExtraction.py, DocstyleDefinition, DocBaseClass.py and DocumentationComment.py) will be unable handle a docstring. This is important so that we can yield a RESULT with a beautiful message in the bear.These were the biggest achievements which I consider the completion factor of this project. Hence, achieving the final/stretch goal as mentioned above.
coala
e41d6b5 DocumentationExtraction.py: Diff cut-off fix
c79ec5a DocumentationComment.py: Improve assemble()
fa26911 DocumentationAPI: Support for :raises xyz:
6abf8a0 DocumentationComment.py: Add in-line comment
bac0c3e DocumentationComment.py: Pass indent
526af97 DocumentationComment: Add conditional for None
f3f613a DocumentationComment.py: Accept position
fa7bd17 DocumentationComment: Fix missing ending colon
d79e497 DocBaseClass: Add DocBaseClass
ffba831 DocumentationComment.py: Add blankline padding
cebe4f2 DocumentationAPI: Ignore triple quote strings
0f81583 DocumentationAPI: Add MalformedComment
070a19e DocumentationAPI: Add padding and type
coala-bears
7ad62fb Add allow_missing_func_desc
40de247 DocumentationStyleBear.py: Amend position
314dfdf DocumentationStyleBear: Use DocBaseClass
40cd086 DocumentationStyleBear: Add expand_one_liners
112fa7d Add DocGrammarBear for docstrings
dccce31 DocStyleBear: Add MalformedComment support
89b5913 DocumentationStyleBear: Add blankline support
There are still some quirks need to be done with DocStyleBear and DocGrammarBear.
DocStyleBear is adding r if the docstring is a raw string. See here for info.DocGrammarBear doesn’t works with well if there are some acronyms.Next is, if everything is sorted I will add DocStyleBear and DocGrammarBear into .coafile of coala. I really want that my work should be used somewhere(at least in coala and coala-bears repo).
Well I felt awesome to get everything done in time. But now Im feeling jobless xD. I guess I will go on a review sprint and help my other GSoC coalians.
Lastly, I wanna speak about my other GSoC collegues. They had also done a great job with their projects. You can read alot about us @blog.coala.io. Also If any of this sounds interesting to you. How about joining us next? @coala.io/newcomer.
That’s it folks!
Till next time see yaa!!
Hi Guys!, How you doing?
It’s been 4 weeks of CODING PHASE-3 and it’s evaluation time again, this is the final one. So from 21st 9:30pm, Evaluation links will become active both me and my mentor have to fill a Q & A form ^_^. In this blog I will be sumarizing my GSoC’2017’s work of last 2 weeks. Let’s begin!!
The deadline of achieving the milestones set by my organization is 21st August. The big thing was DocumentationAPI now has support for automatic padding and docstring type. Which tells us about the trailing no. of blank lines before or after the docstring and also about the type of docstring it is: function level or class level. By using these, now we can have blank lines detected and fixed according to PEP-257. Last 2 weeks was mostly about bug fixes.
DocumentationAPI was creating a bug. It’s end marker was taken as the starting of a new docstring. Seems like the patch which I submitted in PHASE-1 to ignore these string literals was creating this. So I found the other way around. We now Ignore the whole DocComment instead of ignoring it by regex(Which was the case previously). So a PR reverting the previous changes and applying a new solution was made and merged.PHASE-2 was breaking a corner case. Which we thought could be fixed seperately. But it wasn’t like that. So finally we came to a conclusion that DocumentationAPI couldn’t fix docstrings if their markers are faulty. As markers are the only thing by which drives DocumentationAPI to find docstrings inside a file, we now just yield a RESULT with beautiful message which describes that markers are faulty. So a PR reverting the previous changes and applying a new solution was made and merged.This was it!! I have successfully achieved my milestone of PHASE-3. You can see my progress here. And here’s how my burndown chart looks like.
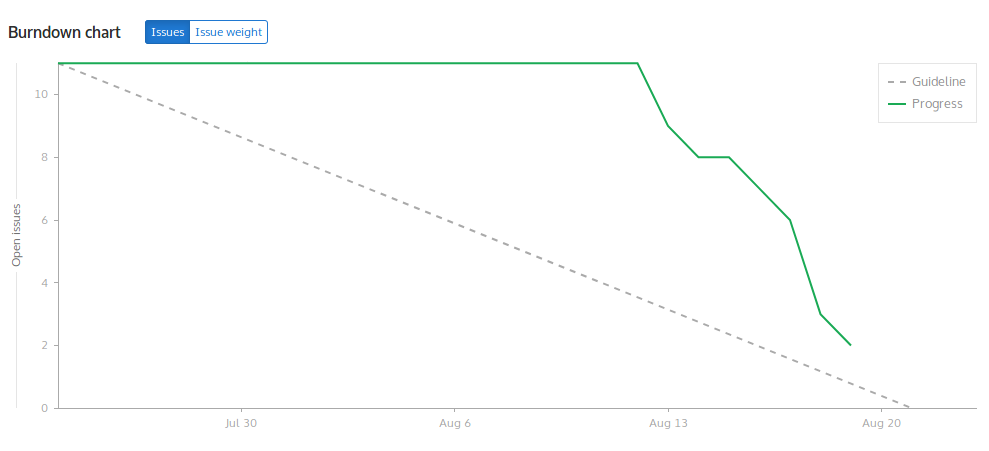 Yay! I did it!
Yay! I did it!
Yes you read it correctly. I completed one of the biggest stretch goal which I had a thought since PHASE-1. It was about giving an error handling mechanism to DocumentationAPI. So we now have MalformedComment class which can be yielded if there is some error in parsing the docstring by DocumentationAPI. Which contains attributes like error message and line number, so these can be yielded on the bear part. A PR has been made and merged.
There’s still one more week remaining for hard deadline of August 29. I was thinking about doing some more quirks to DocGrammarBear and DocStyleBear which will polish my project and a review sprint ;) You can see all progress about stretch goals here!
There were some up and downs in PHASE-2 I nearly failed the milestone. But
Why do we fall? So we can learn to pick ourself’s up - Alfred
Kudos to….Both of my mentors SanketDG & NiklasMM for achieving this milestone together. Couldn’t have done this without them. We made 2 calls a week to discuss about progress and to answer my queries one on one, which is the sole reason of this project being done in time.
I don’t know where this journey ends. It’s feels like it had just begun and opened up a new chapter to fill ;) I will soon write another blog wrapping up about my overall GSoC journey.
Till next time. See Yaa!!
Hello!
It’s very exciting right now! I’m almost at the end of Phase 3!
What I’ve achived so far:
Do (N)othing as an action--no-color flag, an old bug. http://imgur.com/BWzn0meAlso, I’ve reviewed many prs in this period of time!
I hope all of my GSoC collegues finish their assignements in time as I hope to do it!
I’ll make a last post at the end of the phase! I hope I see you there, reading it!
Have a nice time!
Although it is super fun to work with opensource projects, it can get pretty tiresome on the project maintainers after reaching a certain degree of popularity. Projects start to draw the attention of more and more young aspirants and managing the review process can be a pain in the arse.
Here’s to gitmate, we have an easier workflow at coala.io and gitmate.io. Coming to the end of GSoC, it’s been really a lot of pleasure working with Lasse, Fabian and others. They really stood out for help whenever asked for.
I’ve been working on plugins and some final groundwork on a better gitmate. The maintainance of rebase is a bit of a problem on large repositories with thousands of pull requests and merging them, rebasing them, etc. Well now, rebasing a pull request is as easy as commenting @gitmate-bot rebase on the pull request, and voila the heavy lifting job would be done for you. We’ve initially had thoughts about automagically rebasing all open pull requests when an old one was merged, but this might lead to unnecessary use of power on the branches. Henceforth, we just stuck to rebasing them only when asked for. Oh and BTW, all our code is open-source and available at code.gitmate.io. And for the rebase plugin, we use a docker container that pulls the code, and rebases them, and pushes the code onto the remote branch.
That’s all for now.
Let’s rebase. was originally published in My New Roots.. on Medium, where people are continuing the conversation by highlighting and responding to this story.
Hey guys, It’s been 2 weeks since 2nd evaluation. And this is my Coding Phase-3 Mid Month summary. Before I begin with the summary, I just wanna share with you guys that I nearly passed my 2nd evaluation. My bad, I wasn’t able to achieve my last issue, it turns out the issue’s solution was designing the API rather than what I proposed earlier.
It sucks!! Well at first I really got tensed what will the org. admins decide. But it turns out they understood the situation and believed in me that I will still achieve my final goal. Ofcourse! I will not let them down :) . Thanks to org. admins and my mentors for understanding why I wasn’t able to achieve it. At the end it all turned out well, I’m quite happy about how the final solution turned out to be. Also this solution is the biggest patch of my GSoC experience, which introduced 2 new features to the Documentation API. Kind of an achievement for me ^_^
Originally! the only objective for me this month was to implement DocGrammarBear. Which will check for grammatical errors inside the DocumentationComment’s descriptions. But most of the time I spent on clearing the issue which got a bit off-scheduled from my previous milestone.
function vs class. According to PEP-257 class docstrings should be followed by a blank line and function docstrings should never have any blank lines before of after. This issue got so stretched that I ended up implementing 2 new features to the DocumentationAPI.
function, class or others.These both additions were important inorder to solve this issue perfectly. A PR has been made and is close to being merged.
DocGrammarBear which will check for grammatical errors inside the DocumentationComment’s description. PR is ready and close to merge. Also I made an asciinema so you can see this bear in action.These were the 2 major objectives of this month. I think I can achieve my final milestone. As everything is back on schedule.
There are 2 bugs regarding DocumentationAPI which still needs be taken care of. First, Ignoring string literal solution kind of created a bug with its last marker being taken as the start of new docstring. Second, We kinda broke the corner case of all docstrings with java docstyle bug fix. Need to fix it or revert this and raise an error message. That’s it guys!
Till next time! See Yaa!!
Hey everyone! I’m back with another post describing my GSoC journey so far since the last update (released in the final week of Phase 2). Here’s all that happened since then:
language setting values reducing the amount of information the users have to input.As I mentioned in my previous post, this phase involves improvements in existing interface of coala-quickstart. I’m trying to finish all the tasks mentioned in my proposal as soon as possible and manage some time to complete some stretch goals and finally make a release of coala-quickstart ![]()
We’ve finally managed to clear the Phase 2 evaluations.

The last phase i.e. Phase 3 has begun and we’re off with a good start.
We’ve introduced 2 bears with 1 bear remaining. Go check them out and report bugs if you’ve found any :P.
CSScomb is a coding style formatter for CSS. You can easily write your own configuration to make your style sheets beautiful and consistent.
HTTPolice is a linter for HTTP requests and responses. It checks them for conformance to standards and best practices.
Checks HTML code with htmlhint for possible problems. Attempts to catch
little mistakes and enforces a code style guide on HTML files.
We’re planning for some crucial bug fixes. This wouldn’t have been possible without my mentor @Makman2. I’m forward to the final evaluations and I hope everything turns out well.
Hey There! Hope you’re doing great.
So we are in final phase of GSoC and I’ve finished several things till now. Firstly I modified the coala-html CSS to use coalaCSS and styled the navigation accordingly. It now used tabbed navigation which is consistent with coala websites. There are now card views for results and files. Diffs are shown in result tab as well.
The next important thing was to implement an omni search power, which should be powerful enough to search either file, bear or severity and filter the correct search results. So now its a lot more easy to conduct searches in the results tab.
The coming week will be mostly about documentation and bug fixing.
I’ll keep updating the blog.
Hi guys, it’s been my first week into the last phase of GSoC 2017. I’ve been working on writing plugins all day. The first one was to maintain synchronisation between Pull Requests and their related Issues.
It’s been so much fun wiring up a complex regex that could figure out the responsible issues and hell yeah, it’s part of IGitt now. The second one was something that would periodically check for activity on pull requests and issues. If it finds someone’s slacking behind, it labels them as stale. ✌🏻 So that we could easily filter the stale ones behind. Gosh, celery beat scheduling is real fun. 😜
The third one is a plugin that automatically adds approval label on pull requests once the head commit passes all tests. This is attributed to a big change for quickly finding approved ones and merging them.
The coming weeks of GSoC would be wiring up a plugin to find merge request conflicts between one another. And another one to find and rebase approved pull requests when master gets updated.
Sorry for a short post, guys. I promise the next ones to be a bit off the edge and exciting. See ya’ later.
Plugins, plugins everywhere. was originally published in My New Roots.. on Medium, where people are continuing the conversation by highlighting and responding to this story.
Hello again!
As the title says, I’m on Phase 3! Right now I want to add again Executing section <section>... . This was deleted when I changed the ouput. The feedback was that this should be added back.
Then, I want that Chain actions be by default for users. In this way the user can choose to apply a single or multiple actions.
And the last think I want to add is Generate Patches. When you choose this action, you can apply more patches that are different. Something like Apply the patch ('capitalize') and so on (mockup)
See ya in 2 weeks!
This post is part of my GSOC journey in coala.
Because aspect is still new and experimental, many things around it is still untested. Also, not all bear in coala (read: none of them) support aspect. And it will be a long time before it happen. So I think it’s important to make the migration process became more easy.
In this phase, I try to polish up feature so hopefully it will became more sane to be used. Of course there are still many missing things that I don’t think of now, but hopefully I can catch them and add follow up patches. The polishing up could be separated to users perspective and developer perspective:
As mentioned before, aspect ready bear is still a rare species compared to number of aspect definition in coala. This make it very possible to request an aspect that doesn’t have any bear that support it. We need to warn user if this happen.
https://github.com/coala/coala/pull/4657
Funny fact I just learn that for...else syntax
is a thing!
Make sure users is informed what happen (if something goes wrong). Cases like
setting bears and aspects setting at the same time will ignore the bears
setting and missing or invalid language setting should throw a warning logs.
https://github.com/coala/coala/pull/4582
I also use this opportunity to refactor the verification code into its own function instead of separated into various function in order to make it more easier to read (hopefully).
I write a help page on how to configure aspect and list of required setting.
https://github.com/coala/documentation/pull/462
Showcase aspect in progress, best tutorial is a live project!
WIP, should be possible after all PR is merged
A docs containing example of a aspectized bear
https://github.com/coala/coala/pull/4666
This is a bit of quality-of-life feature but still pretty important to make sure bear got aspectized easily. This will map a bear setting with aspect.
https://github.com/coala/coala/pull/4662
In here I write a test that run coala with aspect configuration to make sure
everything work correctly.
In coala/coala itself, I write an end-to-end test that call coala cli to run
with aspect. The purpose is to make sure every component related to aspect
atleast can run without error.
The second part is to create a showcase project like from the user perspective. Ideally it could automatically update along with coala.
Phase 2 is coming to an end today (24’th of July, 11:30 PM IST). It had been an intensive and healthy work-period with a high steep-learning curve. Let me reflect on my journey throughout the month.
vulture previously saved the defined_classes in the defined_functions list.
I just needed to change the visitClassDef function which is triggered
whenever ast finds any Class Definition node.
Changing the entry_point did the work. :-)
So, our plan was to make whitelists for some modules default based on whether or not thaat corresponding module was imported or not.
In the previous phase, we started shipping vulture as a package. Because of the change, we could now ship additional data with the package, like the
Perhaps, the most important part of my GSoC Proposal. The idea was to implement such a function which if given an ast node could find it’s end. For demo purposes, we started source. From the first commit [here] to the current implementation, there is affiliated an impressive amount of research, debigging and creativity (special credits to @jendrikseipp).
vulture stores dead code in a special data structure - Item - a lightwight
representation of the ast node. Previously, Item inherited from str
although there was no absolute need of doing so, and changing it would give us
more command and flexibilty with the design. So, we decided to change it.
The implementation was pretty basic. You may see the changes here:commit
This required me to run vulture over a few web-apps powered by both, flask
and django. Analysing flasky, the book on flask, we uncovered several
interesting facts and surprisingly, we ended up making a whitelist for
the unittest library.
I read @damngamerz post on EuroPython and felt pretty thrilled. I also recieved the news that we are gonna hack PyCon India (or Pune) and make it coalaCon. We will also get coala stickers. Yay!
It has been a pretty awesome journey up till now. I really accredit this to both, my mentor @jendrikseipp and student-admin @jayvdb and to the awesome coala community where every one is so open minded and intelligent.
Thanks! :-)
Hey there guys ;),
The second phase for the google summer of code is over, and it was though. I clearly did not start well, “more than one and a half week of inactivity”. This post is about what I was able to achieve during the time remaining time.
This is what was planned for this phase:
I had a very limited time as explained in my previous post, and is what was done. The Root.Formatting was implemented along with all its subaspects and here is sub-aspect tree representing it.
The Root.Smell and Root.Spelling were refactored and improved and here is the end result:
Code reviews:
I had a review sprint In the meantime. I did it because i wanted to get reviews for my PR as soon as possible and it was so much fun; I think i will do that at least every two weeks ;). Here are the golden rules of code reviews:
“Don’t stay idle waiting for someone to review your PR, be the reviewer, review someone else’ s PR; the more you do that, the sooner you get reviews.”
“The bigger your PR, the less reviews you get and the longer it takes to get merged”
Upcoming
More aspects, more docs and bears’ results annotation. ;).
Summary:
This was a really though phase for me, I didn’t have enough time, but i was able to do something and that is all thanks to Lasse, John, Max, Stefan, Udayan and Yash; guys thanks a ton.
Looking forward evaluation, let’s hope it turns out well ;).
See you soon.




